The summary is that it's a cache attached to the memory controllers, rather than the CPUs, so it doesn't have to worry about cache coherency so much. This could be useful for shared memory parallelism.
Since it is attached to the memory controller, one could argue that it is truly the final level of the cache hierarchy and the term infinity is not only a marketing term.
But then you could add another level of slower (but still faster than RAM) and larger cache. So it is after all the CPU caches, but the first of all the memory caches. A more mathematically correct name would be L_omega.
AMD named their memory fabric "infinity fabric" for marketing reasons. So when they developed their memory attached cache solution (which lives in the memory fabric, unlike a traditional cache), the obvious marketing name is "infinity cache"
The main advantage of a memory attached cache is that it's cheaper than a regular cache, and can even be put on a seperate die, allowing you to have much more of it.
AMDs previous memory fabric from the early 2000s was called "Hyper Transport", which has a confusing overlap with Intel's Hyper Threading, but I think AMD actually bet intel to the name by a few years.
Infinity Fabric is, in fact, the current superset of HyperTransport. HyperTransport is an IO architecture for chip to chip communication and has been used by pretty much everyone. It's also an open spec and has a consortium managing it.
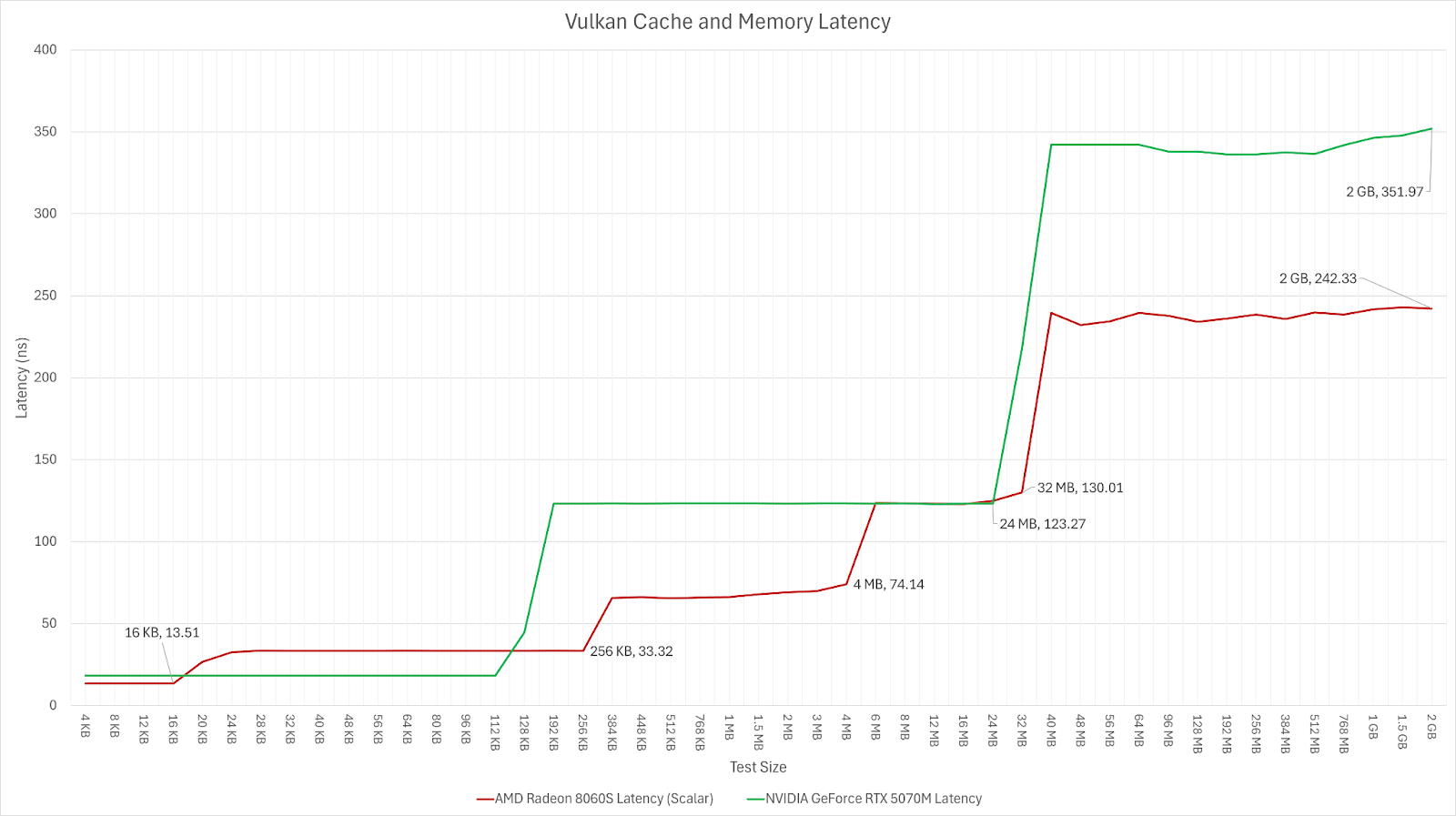
Not sure if ditching infinity cache/L3 for a bigger L2 would make sense. It seems at least plausible to me that growing the L2 cache that much would make its latency worse, thus losing most of what has been gained. In the image you linked, Nvidia's L2 latency is like twice as high as AMD's!
Keep in mind that the 'big' desktop chips have bigger caches too. The L2 on a 5080 and 'L3' on a 9070 XT are both 64 MB. Additionally, AMD has already been growing the L2, going to 8 MB on the 9070 XT vs. 4 MB on the 7800 XT and 6800 XT.
To clarify, the idea that AMD is ditching IC is not mine, I find it puzzling too.
Their marketing materials to OEMs have been leaked, and they no longer mention IC at all, instead proudly displaying (much higher) L2 amounts per GPU. This of course doesn't necessarily mean that they are definitely removing it, but it certainly hints at that.
Despite this APU being deeply interesting to people who want to do local AI, anecdotally I hear that it’s hard to get models to run on it.
Why would AMD not have focused everything it possibly has on demonstrating and documenting and fixing and showing and smoothing the path for AI on their systems?
Why does AMD come across as so generally clueless when it comes to giving developers what they want, compared to Nvidia?
AMD should do whatever it takes to avoid these sort of situations:
I have a Strix Halo based HP ZBook G1A and it's been pretty easy getting local models to run on it. Training small LLMs on it has been a bit harder but doable as well. Mind you, I 'only' have 64 GB with mine.
Under Linux, getting LM Studio to work using the Vulkan backend was trivial. Llama.cpp was a bit more involved. ROCm worked surprisingly well with Arch — I would credit the package maintainers. The only hard part was sorting out Python packaging for PyTorch (use local packages with system's ROCm).
I wouldn't say it's perfect but it's definitely not as bad as it used to be. I think the biggest downside is the difference in environment when you use this as a dev machine and then run the models on NVIDIA hardware for prod.
Can you share a bit more on the small LLMs you've trained? I'm interested in the applicability of current consumer hardware for local training and finetuning.
I'm not the AI expert in the company but one of my colleagues creates image segmentation models for our specific use case. I've been able to run the PyTorch training code on my computer without any issues. These are smaller models that are destined to run on Jetson boards so they're limited compared to larger LLMs.
edit: just to be clear, I can't train anything competitive with even the smallest LLMs.
"The AMD Ryzen™ AI Max+ processor is the first (and only) Windows AI PC processor capable of running large language models up to 235 Billion parameters in size. This includes support for popular models such as: Open AI's GPT-OSS 120B and Z.ai Org's GLM 4.5 Air. The large unified memory pool also allows models (up to 128 Billion parameters) to run at their maximum context length (which is a memory intensive feature) - enabling and empowering use cases involving tool-calling, MCP and agentic workflows - all available today. "
GPT-OSS 120B MXFP4 : up to 44 tk/s
GPT-OSS 20B MXFP4 : up to 62 tk/s
Qwen3 235B A22B Thinking Q3 K L : up to 14 tk/s
Qwen3 Coder 30B A3B Q4 K M : up to 66 tk/s
GLM 4.5 Air Q4 K M : up to 16 tk/s
For comparison, a Ryzen 9 8945HS runs that around 21 tokens/sec on pure CPU at price point around $479 (RAM not included), where newer computers with this chip are >$2000 (RAM soldered on).
Strix Halo can only allocate 96GB RAM to the GPU. So GPT-OSS 120B can be ran only at Q6 at best (but activations would need to be partially stored in the CPU mem then).
I bet you're confusing VRAM (the old fixed thing) and GTT (dynamic) memory allocation. Linux amdgpu does GTT just fine. amdgpu_top is an example monitoring app that shows them separately.
Hardware companies are extremely bad at valuing software. The mystery isn't that AMD is bad at it, the mystery is that NVidia is good at it. They also have a probably 30-40 year head start. AMD is trying as much as they can, but changing culture takes time.
ARM, and even moreso the companies that make ARM devices, are terrible at it. And there's a reason for that.
The customers of hardware companies generally don't want to get proprietary software from them, because everybody knows that if they do, the hardware company will try to use it as a lock-in strategy. So if you make something which is proprietary but not amazing, nobody wants to touch it.
There are two ways around this.
The first is that you embrace open source. This is what Intel has traditionally done and it works really well when your hardware is good enough that it's what people will choose when the software is a commodity. It also means you don't have to do all the work yourself because if you're not trying to lock people in then all the community work that normally goes to trying to reverse engineer proprietary nonsense instead goes into making sure that the open source software that runs on your hardware is better than the proprietary software that runs on your competitor's.
The second is that you spend enough money on lock-in software that people are willing to use it. This works temporarily, because it takes a certain amount of time for competitors and the community to make a decent alternative, but what usually happens after that is that you have a problem because you were expecting there to be a moat and then ten thousand people showed up to each throw in a log or a bag of wet cement. Before too long the moat is filled in and you can't it back because it was premised on your thing working and their thing not, so once their thing works, that's the part that isn't under your control. And at that point the customers have a choice and the customers don't like you.
The problem AMD has is that they were kinda sorta trying to do both in GPUs. They'd make some things open source but also keep trying to hide the inner workings of the firmware from the public, which is what people need in order to allow third parties to make great software for them. But the second strategy was never going to work for AMD because a decade ago they didn't have the resources to even try and now Nvidia is the incumbent and the underdog can't execute a lock-in strategy. But the open source thing works fine here and indeed gets everyone on their side and then it's them and the whole world against Nvidia instead of just them against Nvidia. Which they're gradually starting to figure out.
I think ARM is trying to get better at it, they are recruiting software people, that won't have much effect on the drivers for the bits of ARM SoCs that they don't design though.
What ARM should be doing is putting it in their license terms to require the makers of the SoCs to do it, where "it" is making the software open source, because that's the overwhelmingly obvious fit for a company in their position. And for that matter for the makers of the SoCs because none of them are going to put the resources in to make the software great by themselves and you don't want to be handing out footguns to every middle manager who can't see that.
> Why does AMD come across as so generally clueless when it comes to giving developers what they want, compared to Nvidia?
I have some theories. Firstly, Nvidia was smart enough to have a unified compute GPU architecture across all its architectures -- consumer and commercial. AMD has this awkward split between CDNA and RDNA. So while AMD is scrambling to get CDNA competitive, RDNA is not getting as much attention as it should. I'm pretty sure its ROCm stack has all kinds of hacks trying to get things working across consumer Radeon devices (which internally are probably not well suited/tuned for compute anyways). AMD is hamstrung by its consumer hardware for now in the AI space.
Secondly, AMD is trying to be "compatible" to Nvidia (via HIP). Sadly this is the same thing that AMD did with Intel in the past. Being compatible is really a bad idea when the market leader (Nvidia) is not interested in standardising and actively pursues optimisations and extensions. AMD will always play catch up.
TL;DR AMD made some bad bets on what the hardware would look like in the future and never thought software was critical like nvidia.
AMD now realizes that software is critical and what future hardware should look like. However it is difficult to catch up with Nvidia, the most valuable company in the world with almost limitless resources to invest in further improving its hardware and software. Even while AMD improves, it will continue to look bad in comparison to Nvidia as state of art keeps getting pushed forward.
radeon historically gimped the double precision less badly than nvidia, one might say radeons were more suited for scientific compute. actual scientific compute that cares about numbers and precision.
idk about bad bets, they were just slow to release rdna for desktop when they had it already for consoles. there wasn't conflict between cdna and rdna, cdna was product for their data center. they slow-walked rdna chips because they were busy selling them to consoles. and they never invested in software like nvidia did. they wanted outside people to make openCL work when nvidia was directly investing.
these kind of amateur takes are like a poor distillation of whatever you read in the hardware news. sorda muddying the waters a bit with your confusion.
While Nvidia's strategic foresight explains why Nvidia is ahead, it doesn't quite capture why the challenge is not something that only AMD can or should tackle alone.
The 7,484+ companies who stand to benefit do not have a good way to split the bill and dogpile a problem that is nearly impossible to progress on without lots of partners adding their perspective via a breadth of use cases. This is why I'm building https://prizeforge.com.
Nvidia didn't do it alone. Industry should not expect or wait on AMD to do it alone. Waiting just means lighting money on fire right now. In return for support, industry can demand more open technology be used across AMD's stack, making overall competition better in response for making AMD competitive.
who is waiting? amd and apple were part of opencl consortium. cuda simply ran away with the prize. amd needs to match nvidia on software spend. that is/was the difference.
It's right there. You're whole mentality is about how one company will fix a problem that they cannot inherently have the expertise to fix. Nvidia fixed that the slow way, building a consortium of partners. This is the mindset of dependents waiting for the world to drop benefits on them. If 7k companies stand to make trillions of dollars, which I hope they do with this level of capex, it makes zero sense to pretend AMD can or should do all the work or can do it as fast or as well. I'm building a new model and you're arguing for what the old model should do.
I don't know why you're getting downvotes on this, my experience matches it. I have an Evo-X2 which has Strix Halo and rocm still doesn't officially support it. "Support" is supposedly coming in 7.0.2 which can be installed as a preview at the moment but people are still getting regular and random GPU Hang errors with it. I'm running Arch and I've had to make a bunch of tasks in a mise.toml so that I don't forget the long list environment variables to override various rocm settings, and even longer list of arcane incantations required to update rocm and PyTorch to versions that actually almost work with each other.
> Another is that people unsportingly write things in cuda.
Whether we like it or not, CUDA is the de-facto standard for these things. I wonder how much effort would it take for a company the size of AMD to dedicate a couple million dollars a year to track CUDA as closely as feasible. A couple million dollars is a rounding error for a leading silicon maker.
Personally I love it but then I'm also working on a cuda to amdgpu compiler. I'm probably the only person doing that with a strix halo on his desk, should be debugging cuda on it shortly.
Yeah. Spectral's CTO is still the #2 contributor to that, https://github.com/ROCm/HIPIFY/graphs/contributors. They tried really hard to make hipify work before accepting that forking clang was necessary. I thought I had an issue raised about hipify needing cuda's own headers to run but I can't find it now.
{kind=link}
https://youtu.be/maH6KZ0YkXU