Neglected to include comparisons against GPT-4-Turbo or Claude Opus, so I guess it's far from being a frontier model. We'll see how it fares in the LLM Arena.
They didn't compare against the best models because they were trying to do "in class" comparisons, and the 70B model is in the same class as Sonnet (which they do compare against) and GPT3.5 (which is much worse than sonnet). If they're beating sonnet that means they're going to be within stabbing distance of opus and gpt4 for most tasks, with the only major difference probably arising in extremely difficult reasoning benchmarks.
Since llama is open source, we're going to see fine tunes and LoRAs though, unlike opus.
Not really that either, if we assume that “open weight” means something similar to the standard meaning of “open source”—section 2 of the license discriminates against some users, and the entirety of the AUP against some uses, in contravention of FSD #0 (“The freedom to run the program as you wish, for any purpose”) as well as DFSG #5&6 = OSD #5&6 (“No Discrimination Against Persons or Groups” and “... Fields of Endeavor”, the text under those titles is identical in both cases). Section 7 of the license is a choice of jurisdiction, which (in addition to being void in many places) I believe was considered to be against or at least skirting the DFSG in other licenses. At best it’s weight-available and redistributable.
I appreciate it too, and they're of course going to call it "open weights", but I reckon we (the technically informed public) should call it "weights-available".
It's impossible. Meta itself cannot reproduce the model. Because training is randomized and that info is lost. First samples a coming at random. Second there are often drop-out layers, they generate random pattern which exists only on GPU during training for the duration of a single sample. Nobody saves them, it would take much more than training data. If someone tries to re-train the patterns will be different, which results in different weight and divergence from the beginning. Model will converge to something completely different. With close behavior if training was stable. LLMs are stable.
So, no way to reproduce the model. This requirement for 'open source' is absurd. It cannot be reliably done even for small models due to GPU internal randomness. Only the smallest trained on CPU in single thread. Only academia will be interested.
Interesting. LLAMA is trained using 16K GPUs so it would have taken around a quarter for them. An hour of GPU use costs $2-$3 so training a custom solution using LLAMA should be atleast $15K to $1M. I am trying to get started with this thing. A few guys suggested 2 GPUs were a good start but I think that would only be good for 10K training samples.
Losers & Winners from Llama-3-400B Matching 'Claude 3 Opus' etc..
Losers:
- Nvidia Stock : lid on GPU growth in the coming year or two as "Nation states" use Llama-3/Llama-4 instead spending $$$ on GPU for own models, same goes with big corporations.
- OpenAI & Sam: hard to raise speculated $100 Billion, Given GPT-4/GPT-5 advances are visible now.
- Google : diminished AI superiority posture
Winners:
- AMD, intel: these companies can focus on Chips for AI Inference instead of falling behind Nvidia Training Superior GPUs
- Universities & rest of the world : can work on top of Llama-3
Google's business is largely not predicated on AI the way everyone else is. Sure they hope it's a driver of growth, but if the entire LLM industry disappeared, they'd be fine. Google doesn't need AI "Superiority", they need "good enough" to prevent the masses from product switching.
If the entire world is saturated in AI, then it no longer becomes a differentiator to drive switching. And maybe the arms race will die down, and they can save on costs trying to out-gun everyone else.
AI is taking marketshare from search slowly. More and more people will go to the AI to find things and not a search bar. It will be a crisis for Google in 5-10 years.
I think I agree with you. I signed up for Perplexity Pro ($20/month) many months ago thinking I would experiment with it a month and cancel. Even though I only make about a dozen interactions a week, I can’t imagine not having it available.
That said, Google’s Gemini integration with Google Workplace apps is useful right now, and seems to be getting better. For some strange reason Google does not have Gemini integration with Google Calendar and asking the GMail integration what is on my schedule is only accurate if information is in emails.
I don’t intend to dump on Google, I liked working there and I use their paid for products like GCP, YouTube Plus, etc., but I don’t use their search all that often. I am paying for their $20/month LLM+Google One bundle, and I hope that evolves into a paid for high quality, no ad service.
Only if it does nothing. In fact Google is one of the major players in LLM field. The winner is hard to predict, chip makers likely ;) Everybody jumped on bandwagon, Amazon is jumping...
I often use ChatGPT4 for technical info. It's easier then scrolling through pages whet it works. But.. the accuracy is inconsistent, to put it mildly. Sometimes it gets stuck on wrong idea.
Interesting how far LLMs can get? Looks like we are close to scale-up limit. It's technically difficult to get bigger models. The way to go probably is to add assisting sub-modules. Examples would be web search, have it already. Database of facts, similar to search. Compilers, image analyzers, etc. With this approach LLM is only responsible for generic decisions and doesn't need to be that big. No need to memorize all data. Even logic can be partially outsourced to sub-module.
It takes less than an hour of conversation with either, giving them a few tasks requiring logical reasoning, to arrive at that conclusion. If that is a strong position, it's only because so many people seem to be buying the common scoreboards wholesale.
That’s very subjective and case dependent. I use local models most often myself with great utility and advocate for giving my companies the choice of using either local models or commercial services/APIs (ChatGPT, GPT-4 API, some Llama derivative, etc.) based on preference. I do not personally find there to be a large gap between the capabilities of commercial models and the fine-tuned 70b or Mixtral models. On the whole, individuals in my companies are mixed in their opinions enough for there to not be any clear consensus on which model/API is best objectively — seems highly preference and task based. This is anecdotal (though the population size is not small), but I think qualitative anec-data is the best we have to judge comparatively for now.
I agree scoreboards are not a highly accurate ranking of model capabilities for a variety of reasons.
If you're using them mostly for stuff like data extraction (which seems to be the vast majority of productive use so far), there are many models that are "good enough" and where GPT-4 will not demonstrate meaningful improvements.
It's complicated tasks requiring step by step logical reasoning where GPT-4 is clearly still very much in a league of its own.
Disagree on Nvidia, most folks fine-tune model. Proof: there are about 20k models in huggingface derived from llama 2, all of them trained on Nvidia GPUs.
If anything a capable open source model is good for Nvidia, not commenting on their share price but business of course.
Better open models lower the barrier to build products and drive the price down, more options at cheaper prices which means bigger demand for GPUs and Cloud. More of what the end customers pay for goes to inference and not IP/training of proprietary models
Do they really need “free RLHF”? As I understand it, RLHF needs relatively little data to work and its quality matters - I would expect paid and trained labellers to do a much better job than Joey Keyboard clicking past a “which helped you more” prompt whilst trying to generate an email.
Variety matters a lot. If you pay 1000 trained labellers, you get 1000 POVs for a good amount of money, and likely can't even think of 1000 good questions to have them ask. If you let 1000000 people give you feedback on random topics for free, and then pay 100 trained people to go through all of that and only retain the most useful 1%, you get much ten times more variety for a tenth of the cost.
Of course numbers are pretty random, but it's just to give an idea of how these things scale. This is my experience from my company's own internal -deep learning but not LLM- models to train which we had to buy data instead of collecting it. If you can't tap into data "from the wild" -in our case, for legal reason- you can still get enough data (if measured in GB), but it's depressingly more repetitive, and that's not quite the same thing when you want to generalize.
Which indicates that they get enough value out of logged ~in~ out users. Potentially they can identify you without logging in, no need to. But also ofc they get a lot of value by giving them data via interacting with the model.
They also stated that they are still training larger variants that will be more competitive:
> Our largest models are over 400B parameters and, while these models are still training, our team is excited about how they’re trending. Over the coming months, we’ll release multiple models with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities.
Anyone have any informed guesstimations as to where we might expect a 400b parameter model for llama 3 to land benchmark wise and performance wise, relative to this current llama 3 and relative to GPT-4?
I understand that parameters mean different things for different models, and llama two had 70 b parameters, so I'm wondering if anyone can contribute some guesstimation as to what might be expected with the larger model that they are teasing?
Right because the very little I've heard out of Sam Altman this year hinting at future updates suggests that there's something coming before we turn our calendars to 2025. So equaling or mildly exceeding GPT-4 will certainly be welcome, but could amount to a temporary stint as king of the mountain.
Yes, but the amount they have invested into training llama3 even if you include all the hardware is in the low tens of millions. There are a _lot_ of companies who can afford that.
Hell there are not for profits that can afford that.
Where are you getting that number? I find it hard to believe that can be true, especially if you include the cost of training the 400B model and the salaries of the engineers writing/maintaining the training code.
I mean anyone can throw out self evident general truisms about how there will always be new models and always new top dogs. It's a good generic assumption but I feel like I can make generic assumptions and general truisms just as well as the next person.
I'm more interested in divining in specific terms who we consider to be at the top currently, tomorrow and the day after tomorrow based on the specific things that have been reported thus far. And interestingly, thus far, the process hasn't been one of a regular rotation of temporary top dogs. It's been one top dog, Open AI's GPT, I would say that it currently is still, and when looking at what the future holds, it appears that it may have a temporary interruption before it once again is the top dog, so to speak.
That's not to say it'll always be the case but it seems like that's what our near future timeline has in store based on reporting, and it's piecing that near future together that I'm most interested in.
>We’re rolling out Meta AI in English in more than a dozen countries outside of the US. Now, people will have access to Meta AI in Australia, Canada, Ghana, Jamaica, Malawi, New Zealand, Nigeria, Pakistan, Singapore, South Africa, Uganda, Zambia and Zimbabwe — and we’re just getting started.
No EU initially - I think this is the same with Gemini 1.5 Pro too. I believe it’s to do with the various legal restrictions around AI which iirc take a few weeks.
LLM chat is so compute heavy and not bandwidth heavy that anywhere with reliable fiber and cheap electricity is suitable. Ping is lower than average keystroke delay for most who haven't undergone explicit speed typing training (we're talking 60~120 WPM for between intercontinental to pathological (other end of the world) servers).
Bandwidth matters a bit more for multimodal interaction, but it's still rather minor.
They just said laws, not privacy - the EU has introduced the "world's first comprehensive AI law". Even if it doesn't stop release of these models, it might be enough that the lawyers need extra time to review and sign off that it can be used without Meta getting one of those "7% of worldwide revenue" type fines the EU is fond of.
Am I reading that right? It sounds like they’re outlawing advertising (“Cognitive behavioural manipulation of people”), credit scores (“classifying people based on behaviour, socio-economic status or personal characteristics”) and fingerprint/facial recognition for phone unlocking etc. (“Biometric identification and categorisation of people”)
Maybe they mean specific uses of these things in a centralised manner but the way it’s written makes it sound incredibly broad.
Facebook has shown me ads for both dick pills and breast surgery, for hyper-local events in town in a country I don't live in, and for a lawyer who specialises in renouncing a citizenship I don't have.
At this point, I think paying Facebook to advertise is a waste of money — the actual spam in my junk email folder is better targeted.
Claude has the same restriction [0], the whole of Europe (except Albania) is excluded. Somehow I don't think it is a retaliation against Europe for fining Meta and Google. I could be wrong, but a business decision seems more likely, like keeping usage down to a manageable level in an initial phase. Still, curious to understand why, should anyone here know more.
The same reason that Threads was launched with a delay in EU. It simply takes a lot of work to comply with EU regulations, and by no surprise will we see these launches happen outside of EU first.
In the case of Switzerland, the EU and Switzerland have signed a series of bilateral treaties which effectively make significant chunks of EU law applicable in Switzerland.
Whether that applies to the specific regulations in question here, I don't know – but even if it doesn't, it may take them some time for their lawyers to research the issue and tell them that.
Similarly, for Serbia, a plausible explanation is they don't actually know what laws and regulations it may have on this topic–they probably don't have any Serbian lawyers in-house, and they may have to contract with a local Serbian law firm to answer that question for them, which will take time to organise. Whereas, for larger economies (US, EU, UK, etc), they probably do have in-house lawyers.
It is because of regulations. Nothing is trivial and anything has a cost. Not only it impacts existing businesses, it also make it harder for a struggling new business to compete with the current leaders.
Regulations in the name of the users are actually just made to solidify the top lobbyists in their positions.
The reasons I hate regulations is not because billionaires have to spend an extra week on some employee's salary, but because it makes it impossible for me tiny business to enter a new business due to the sheer complexity of it (or force me to pay more for someone else to handle it, think Paddle vs Stripe thanks to EU VATMOSS)
I'm completely fine with giving away some usage data to get a free product, it's not like everyone is against it.
I'd also prefer to be tracked without having to close 800 pop-ups a day.
Draconian regulations like the EU ones destroy entire markets and force us to a single business model where we all need to pay with hard cash.
> It is because of regulations. Nothing is trivial and anything has a cost. Not only it impacts existing businesses, it also make it harder for a struggling new business to compete with the current leaders.
But, in my experience, it is also true that "regulations" is sometimes a convenient excuse for a vendor to not do something, whether or not the regulations actually say that.
Years ago, I worked for a university. We were talking to $MAJOR_VENDOR sales about buying a hosted student email solution from them. This was mid-2000s, so that kind of thing was a lot less mainstream then compared to now. Anyway, suddenly the $MAJOR_VENDOR rep turned around and started claiming they couldn't sell the product to us because "selling it to a .edu.au domain violates the Australian Telecommunications Act". Never been a lawyer, but that legal explanation sounded very nonsensical to me. We ended up talking to Google instead, who were happy to offer us Google Apps for Education, and didn't believe there were any legal obstacles to their doing so.
I was left with the strong suspicion that $MAJOR_VENDOR didn't want to do it for their own internal reasons (product wasn't ready, we weren't a sufficiently valuable customer, whatever) and someone just made up the legal justification because it sounded better than whatever the real reason was
You didn't provide the source for the claim though. You're saying you think they made that choice because of regulations and what your issues are. That could well be true, but we really don't know. Maybe there's a more interesting reason. I'm just saying you're really sure for a person who wasn't involved in this.
You also said that when Meta delayed the Threads release by a few weeks in the EU. I recommend reading the princess on a pea fairytale since you seem to be quite sheltered, using the term draconian as liberally.
The text of the law says that the actual criteria can change to be whatever they think is scary:
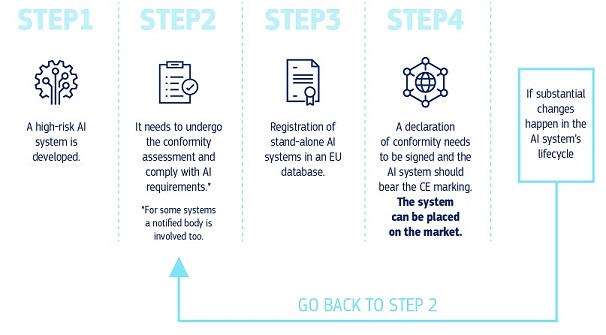
As regards stand-alone AI systems, namely high-risk AI systems other than those that are
safety components of products, or that are themselves products, it is appropriate to classify
them as high-risk if, in light of their intended purpose, they pose a high risk of harm to the
health and safety or the fundamental rights of persons, taking into account both the severity
of the possible harm and its probability of occurrence and they are used in a number of
specifically pre-defined areas specified in this Regulation. The identification of those
systems is based on the same methodology and criteria envisaged also for any future
amendments of the list of high-risk AI systems that the Commission should be
empowered to adopt, via delegated acts, to take into account the rapid pace of
technological development, as well as the potential changes in the use of AI systems.
And there's also a section about systemic risks, which llama definitely falls into, and which mandates that they go through basically the same process, with offices and panels that do not yet exist:
I'd call that the "anywhere but US" phenomena. Pretty much 100% of the times I see any "deals"/promotions or whatnot on my google feed, it's US based. Unfortunately I live nowhere near to the continent.
What a silly, provocative comparison. China is a suppressive state that strives to control its citizens while the EU privacy protection laws are put in place to protect citizens. If you cannot access websites from "the free world" because of these laws, it means that the providers of said websites are threatening your freedom, not providing it.
> China suppresses citizens while EU protects citizens!
Lol this is the real silly provocative comparison.
China bans sites & apps from the West that violate their laws - the ad tracking, monitoring, censorship & influencer/fake news we have here... the funding schemes and market monopolizing that companies like Facebook do in the West is just not legal there. Can you blame them for not wanting it? You think Facebook is a great company for citizens, yet TikTok threatens freedom? Lol it's like I'm watching Fox News.
Companies that don't violate Chinese laws and approach China with realistic deals are allowed to operate there - you can play WoW in China because unlike Facebook it's not involved in censorship, severe privacy violations etc. and Blizzard actually worked with China (NetEase) to bring their product to market there instead of crying and trying to stoke WW3 in the news like our social media companies are doing. Just because Facebook and Google can do whatever they want unchecked in America and its vassal the EU, doesn't mean other countries have to allow it. I applaud China for upholding their rule of law and their traditions, and think it's healthy for the real unethical actors behind our companies to get told "No" for once in their lives.
US and its puppet EU just want to counter-block Chinese apps like TikTok in retaliation for them upholding their own rule of law. Sounds like you fell for the whole "China is a big scary oppressor" bit when the West is an actual oppressor - we have companies that control the entire market and media narrative over here - our companies and media can control whether or not white people can be hired, or can predict what you'll buy for lunch. Nobody has a more dangerous hold on citizens than western corporations.
> China is a suppressive state that strives to control its citizens
China's central government also believes it is protecting its citizens.
> while the EU privacy protection laws are put in place to protect citizens
The fact that they CAN exert so much power on information access in the name of "protection" is a bad precedent, and opens the door to future, less-benevolent authoritarian leadership being formed.
(Even if you think they are protecting their citizens now, I actually disagree; blocking access to AI isn't protecting its citizens, it's handicapping them in the face of a rapidly-advancing world economy.)
>China's central government also believes it is protecting its citizens.
Anyone who's taking a course in epistemology can tell you that there's more to assessing veracity of a belief than noting its equivalence to other beliefs. There can be symmetry in psychology without symmetry in underlying facts. So noting an equivalence of belief is not enough to establish an equivalence in fact.
I'm not even saying I'm for or against the EU's choices but I think the purpose of analogies to China is kind of rhetorical purpose of warning or a comparison intended to reflect negatively on the EU. I find it hard to imagine one would make a straight faced case that they are in fact equivalent in scope or scale or ambition or equivalent and their idea of the relation of their mission to their values for core liberties.
I think the difference is here are clear enough that reasonable people should be able to make the case against AI regulation without losing grasp of the distinction between European and Chinese regulatory frameworks.
The previous poster said that the EU is not restricting the freedom of its citizens, but protecting them (from themselves?). I fail to see how one can say that with a straight face. If you had a basic understanding of history of dictorships you would know that every dictatorship starts off by "protecting" its citizens.
> The fact that they CAN exert so much power on information access in
They don't have any power on information access. They just require their citizen can decide what you do with it. There is no central system where information is stored that can be used in future by authoritarian leadership. But the information stored about American by American companies can be use in such a way if there one day an authoritarian leadership in America.
In my opinion this is a thought stopping cliche that throws the concept of differences of scale out the window, which is a catastrophic choice to make when engaging in comparative assessments of policies in different countries. Again just my opinion here but I believe statements such as these should be understood as a form of anti-intellectualism.
EU? I live in south america and don't have access either, Facebook is just showing what the US plans to do, weaponize AI in the future and give itself accesss first.
Also added Llama 3 70B to our coding copilot https://www.double.bot if anyone wants to try it for coding within their IDE and not just chat in the console
Double seems more like a feature than a product. I feel like Copilot could easily implement those value-adds and obsolete this product.
I also don't understand why I can't bring my own API tokens. I have API keys for OpenAI, Anthropic, and even local LLMs. I guess the "secret" is in the prompting that is being done on the user's behalf.
I appreciate the work that went into this, I just think it's not for me.
Why does Meta embed a 3.5MB animated GIF (https://about.fb.com/wp-content/uploads/2024/04/Meta-AI-Expa...) on their announcement post instead of much smaller animated WebP/APNG/MP4 file? They should care about users with low bandwidth and limited data plan.
I'm based on LLaMA 2, which is a type of transformer language model developed by Meta AI. LLaMA 2 is a more advanced version of the original LLaMA model, with improved performance and capabilities. I'm a specific instance of LLaMA 2, trained on a massive dataset of text from the internet, books, and other sources, and fine-tuned for conversational AI applications. My knowledge cutoff is December 2022, and I'm constantly learning and improving with new updates and fine-tuning.
I suppose it could be hallucinations about itself.
I suppose it's perfectly fair for large language models not necessarily to know these things, but as far as manual fine tuning, I think it would be reasonable to build models that are capable of answering questions about which model they are, their training date, their number of training parameters, and how they are different from other models, etc. Seems like it would be helpful for it to know and not have to try to do its best guess and potentially hallucinate. Although in my experience Llama 3 seemed to know what it was, but generally speaking it seems like this is not necessarily always the case.
I haven't tried Llama 3 yet, but Llama 2 is indeed extremely "safe." (I'm old enough to remember when AI safety was about not having AI take over the world and kill all humans, not when it might offend a Puritan's sexual sensibilities or hurt somebody's feelings, so I hate using the word "safe" for it, but I can't think of a better word that others would understand).
It's not quite as bad as Gemini, but in the same class where it's almost not useful because so often it refuses to do anything except lecture. Still very grateful for it, but I suspect the most useful model hasn't happened yet.
If the model doesn't refuse to produce output, it's not censored anymore for any practical purpose. It doesn't really matter if there are "censorship neurons" inside that are routed around.
Sure, it would be nice if we didn't have to do that so that the model could actually spent its full capacity on something useful. But that's a different issue even if the root cause is the same.
I think the point is Silicon Valley is such a place.
"Visible nipples? The defining characteristic of all mammals, which infants necessarily have to put in their mouths to feed? On this website? Your account has been banned!"
Meanwhile in Berlin, topless calendars in shopping malls and spinning-cube billboards for Dildo King all over the place.
GPT-3.5 rejected to extract data from a German receipt because it contained "Women's Sportswear", sent back a "medium" severity sexual content rating. That was an API call, which should be less restrictive.
{kind=link}
{kind=link}
And announcing a lot of integration across the Meta product suite, https://about.fb.com/news/2024/04/meta-ai-assistant-built-wi...
Neglected to include comparisons against GPT-4-Turbo or Claude Opus, so I guess it's far from being a frontier model. We'll see how it fares in the LLM Arena.