Art imitates life. With coronavirus being the dominate thing on my mind, I found myself wanting to make some art — and also felt drawn to cellular automata.
Here’s something I did this week. It’s a 3D cellular automata made in Metal (Apple’s real-time graphics framework) using a 3D texture and compute shader:
Let me use this thread to advertise my program Logic Life Search that does the same thing. In fact it doesn't just find predecessors but can also be used to prepare SAT instances for finding various other interesting patterns in cellular automata.
One of the best features is that it can treat the rules of the cellular automaton as logical variables as well as the cells of the pattern. So if you're looking for an interesting behaviour that doesn't occur in Life, LLS will find a rule where it does happen.
For years I'm been thinking about something like this in terms of data compression:
Would it be possible to have some sort of cellular automata program that generates the uncompressed data after so many generations.
The compressed data would be the start state of the game field, which over several generations would produce the uncompressed data.
For it to work, you would have to start with the uncompressed data and work backwards. Which is what the author of this article is trying to do with these pictures.
Based on what I can understand from the article, there is no hope for my data compression scheme.
How does this compress data though even if you could easily find parent states? Don't you have to have at least one bit per cell (alive or dead) for your whole grid?
You have some information which is X bits long, so you turn it into a game of life board. Then you find a parent state which is still X bits long. How does that help with compression?
You might be able to start with a much smaller starting state. Like the R pentomino starts with a tiny starting state and runs for a very long time before entering a quiescent state. So your encoding scheme could be just enough info to say "a grid with dimensions h_0 by w_0 filled with bit pattern b_0, run for n generations, then take the bit pattern b_n from the cells in the rectangle with dimensions h_n by w_n with top left corner at x_n y_n from our initial top left corner." As long as h_0 times w_0 is pretty small compared to h_n by w_n you'll come out with compression.
That's really interesting and seems like it could (in theory) work, though it would be challenging and time consuming to actually compress data this way.
oh yeah like the paper says it's doing SAT a lot of times. Nearest I can tell the time complexity for each bit of the output is O(n!) where n is the size of the (unknown and you are solving for it) input bit pattern. So total time complexity is something like O(n! * w_n * h_n) which is BIG and stupid and might make this actually not a way to beat the optimum compression ratio dictated by entropy.
I should explain ... the extent of my knowledge of data compression is pretty nil.
I could tell you how run length encoding works, but that's about it.
More than anything, it's a fantasy compression scheme.
I was originally inspired by rainbow tables (https://en.wikipedia.org/wiki/Rainbow_table) . The idea would be some sort of compression where there would be a table of uncompressed data blobs that map to some sort of hash key. The compressed file would be a sequence of the key.
If you're reading this and you have a working knowledge of data compression, I imagine this is throwing off all sorts of red flags in your head. Feel free to explain why it wouldn't work.
I could see Game of Life as part of a DIY steganography scheme. E.g. I tweet a picture and have some numerals in my tweet called N. You download the picture and convert it via an agreed on protocol to a game of life board, then advance the board by N times. Then you convert the board back to bits and then to text, and find somewhere in the text a "Message begins: XXX. Message ends." Sequence.
I wonder if you would be able to hide messages in superficially normal pictures like that.
I couldn't read this without thinking of πfs (Pi FS).
Pi being an irrational number contains all other numbers. Therefor rather than sending someone a file (eg a video) all you need to do is search the never-ending π and send people the offset instead. 100% compression here we go.
Same problem. The amount of information that you need to specify a compressible offset plus the compressibility of said offset adds up to at least the amount of information you were trying to encode, and no compression happens.
If you ignore either half of the information problem, you can get what looks like compression but really isn't.
Given the looooooooong history of people on the internet not believing that, I preemptively invite you to implement it. If you could make it work there's big money to be made.
It wouldn't be practical even if I were right, but I see the issue with my logic.
My reasoning amounted to "there are infinite repetitions of any sequence in Pi, therefore for any given sequence there must exist one occurrence with a compressible index."
Which, after consideration, I acknowledge is incorrect :)
In this case your starting automata is acting as a program you want to find the smallest one that produces your object as output. It is in general undecidable to know if you found the smallest possible program that produces a given output.
I'd be curious to see code that generates an initial state that when running indefinitely can create a stable state which looks as much as possible like a given image.
That would basically be the "living" representation of the image, as far as game of life rules go.
Start with the target stable state, and add something that, on its own, dies out, far enough from the target stable state to not interfere with it.
You could cheat a tiny bit less by removing a small stable part from the ‘edge’ of the target pattern, firing gliders at it that, just before hitting the smaller target, collide to complete the stable pattern.
I think you can generate many stable patterns by taking this to the extreme: start with an empty target area, and fire gliders at it that collide and add stable parts one by one.
You may need lots of gliders, but since the board is infinite, it’s easy to prevent the separate glider groups from interfering with each other.
Not sure what you mean by DP, but this should in general be possible (granted enough memory & computing power). The problem for me is that stable states have to be fairly sparse, so I'm not sure how you'd get one to really look like anything at all ...
Yes, dynamic programming as mentioned. Good point about the stable states being sparse, meaning we wouldn't be able to get close enough to a good representation of the image.
Please oh please just try it with a dithered image instead of a pure threshold binary choice. Dithering is well accepted as a necessity when downgrading image pixel space for a lot of good reasons and might actually result in some solvable images.
Error diffusion dithering would work very well as initial conditions for many cellular automata rules like Life, especially counting rules (which life is) that stay alive with intermediate numbers of neighbors.
Conway's Life stays alive with 2 or 3 neighbors out of 9, or 2/9 .. 3/9, so gray scales between 22% .. 33% would be the most active.
Halftone screens would have different results, but their regularity might work well with certain CA rules and screens.
PostScript gives you a lot of control over the halftone screen definition.
Halftone screens can use any kind of repeating pattern, there just has to be the proper ratio of white to black pixels to make it look the right brightness. You could even design a set of halftone screen patterns that were precisely matched with a particular cellular automata rule to produce interesting fertile or static patterns. And you can even use any arbitrary pattern for each level, even if they aren't the right brightness, for aesthetic reasons.
The original PostScript LaserWriter was able to efficiently perform pattern fills to print tiled MacDraw images, by defining a custom halftone screen for each tile pixel pattern, that printed precisely the right pixels when you set just the right gray level: the ratio of on pixels to the total number of pixels in the tile. The spot function basically tells the halftone screen machinery what order to turn the dots on as the gray level goes from 1 to 0 (which results is seamless tiling with nearby gray tiles). Take a look at the PostScript header of an old MacDraw file some time to see the really bizarre code that does that by abusing the "setscreen" operator with a contrived spot function. (That was extremely tricky and gave GhostScript problems for years. The trick is documented in Program 15 page 193 of the awesome PostScript "Blue Book", and it uses a lot of memory! It's one of the coolest tricky PostScript hacks I've ever seen!)
>This program demonstrates how to fill an area with a
bitmap pattern using the POSTSCRIPT halftone screen
machinery. The setscreen operator is intended for
halftones and a reasonable default screen is provided by
each POSTSCRIPT implementation. It can also be used for
repeating patterns but the device dependent nature of the
setscreen operator can produce different results on
different printers. As a solution to this problem the
procedure, ‘‘setuserscreen,’’ is defined to provide a
device independent interface to the device dependent
setscreen operator.
>IMPLEMENTATION NOTE: Creating low frequency
screens (below 60 lines per inch in device space) may
require a great deal of memory. On printing devices
with limited memory, a limitcheck error occurs when
storage is exceeded. To avoid this error, it is best to
minimize memory use by specifying a repeating pattern
that is a multiple of 16 bits wide (in the device
x-direction) and a screen angle of zero
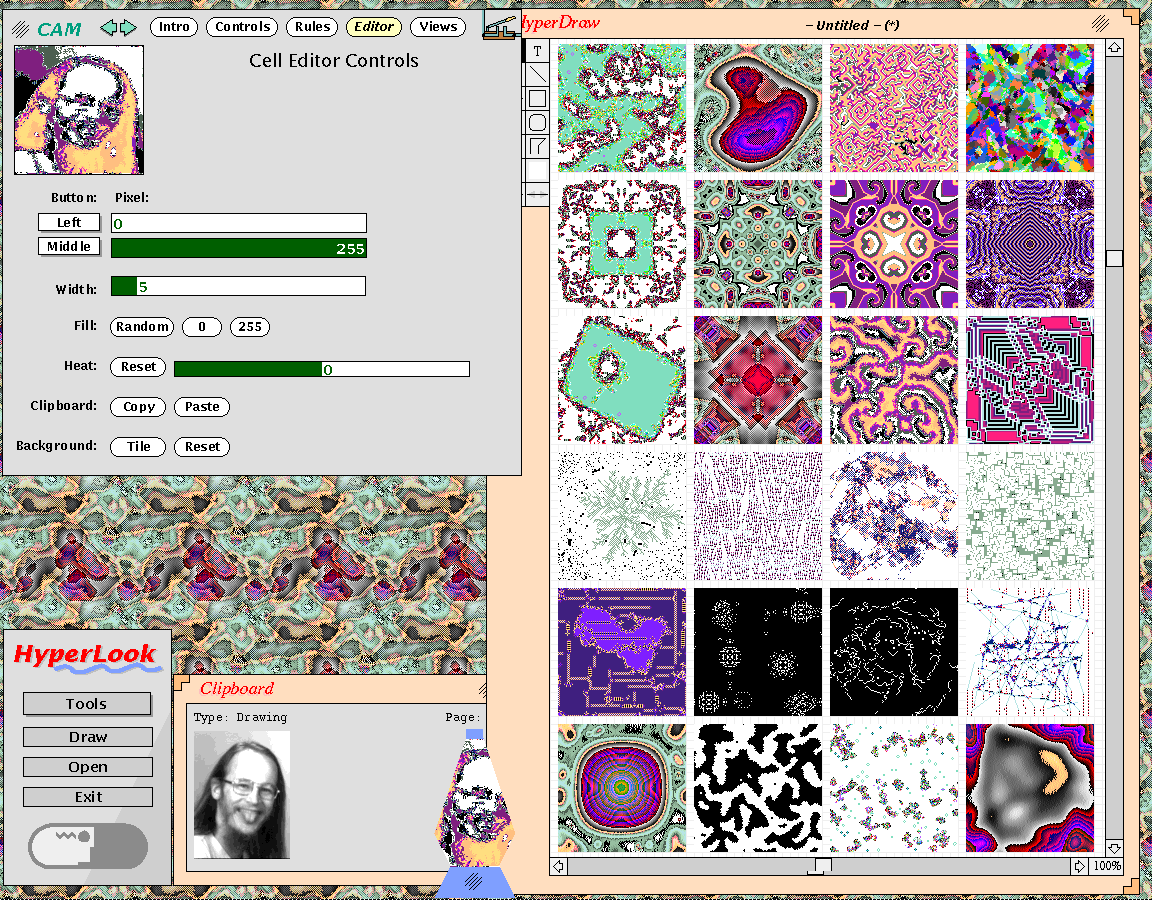
This shows the HyperLook CAM6 interface, which is great for generating tiled screen backgrounds, and a Lava Lamp window I made by copying and pasting the live cellular automata component into a Lava Lamp HyperLook stack whose shape I made with the drawing editor. And the PostScript drawing editor with a bunch of snapshots of different CA rules I copied and pasted out of the simulator. And he's no Mona Lisa, but it also shows the results of applying a cellular automata rule to John Gilmore's cheeky face.
I made this one by pasting a PostScript drawing of a Royal Pine air freshener into a hybrid cellular automata / error diffusion dithering rule, which made nice stink lines, then running it for a while, then pasting the Royal Pine drawing back in on top. That one wraps around so it makes a great screen background too!
Demonstration of SimCity running under the HyperLook user interface development system, based on NeWS PostScript, running on a SPARCstation 2. Includes a demonstration of editing HyperLook graphics and user interfaces, the HyperLook Cellular Automata Machine, and the HyperLook Happy Tool. Also shows The NeWS Toolkit applications PizzaTool and RasterRap. HyperLook developed by Arthur van Hoff and Don Hopkins at the Turing Institute. SimCity ported to Unix and HyperLook by Don Hopkins. HyperLook Cellular Automata Machine, Happy Tool, The NeWS Toolkit, PizzaTool and Raster Rap developed by Don Hopkins. Demonstration, transcript and close captioning by Don Hopkins. Camera and interview by Abbe Don. Taped at the San Francisco Exploratorium.
Since propagation of information is limited to one cell per step, it's possible to speed this up by splitting the image into smaller subimages and solving those first, and then solve the borders between such subimages.
This technique can be used to solve multiple steps as well, the only change is that the border between subimages becomes thicker.
Yeah but for a sufficiently big image I think segregation will help if we do some sort of memoization. But I guess SAT solvers may be doing that too internally.
That's a good point. Life has translation symmetry that the SAT solver can't see. So if copies of the same region appear in your pattern more than once then you could plausibly save the SAT solver time by telling it to use the same predecessor for all of them.
You can see this in the flower image. The target image has a lot of symmetries (reflections, rotations) that also exist in the GoL ruleset. So must be a parent that also has these symmetries. Yet the found solution has none of these symmetries.
It has no parent with the same symmetry, since every neighbour of the centre cell would be the same but a cell can't live or be born with 0 or 4 neighbours.
True, and this is a counterexample to my claim that the parent would retain the symmetry. I think it can be refined though:
The parent still has hor/ver mirror symmetries, and the solution rotated is also a solution. So there is a set of (in this case two) parents that is invariant under the same symmetries.
In general, a parent should still be a parent when any of the targets symmetries are applied. (But it wouldn't necessarily be the same parent).
This can be captured in a SAT by insisting that any symmetry of a solution is also a solution, which adds a lot of new constraints and no new variables, so should help with finding.
This is hard in general for most pictures because they tend to have sections that are too “dense” to sustain life, which thus do not arise naturally. And even when the density is correct, having that many cells close together is a surefire way to get chaos.
I'd loosen the problem a bit myself. After all, the Mona Lisa isn't a solid block of black either. It should be possible to put down a stipple pattern that, by construction, isn't a Garden of Eden pattern for at least one generation. This gives some degrees of freedom in the output. This should make the problem mathematically more tractable, although computationally more difficult since now we're searching a large space rather than being able to pretty quickly just go "nope, no solution".
How far back you could push that, I don't know. One generation before is almost certainly going to look very like the final picture. The "real goal" is almost certainly to get something that doesn't look much like the original for as long as possible, only for it to flash into existence with as little warning as possible. Though you could augment the scheme I describe above by coloring in the large chunk of non-alive spaces with patterns that fully extinguish themselves, which would at least somewhat obscure those portions.
Thats why you can combine them with relational operators.
And then find sets of those combinables that can produce the desired output for most of the time.
That is ones library. It can be adapted to the task.
SAT problems, after all, are in the NP-complete class of problems, which means that they are damn hard to solve with current methods.
...and if they weren't, it would have some very interesting implications for cryptography, one of which is that preimage attacks on hash functions would become much easier --- the SAT instance in this case is one that performs the computation of the function, equating each bit of desired output to equations of each of the input bits.
Honestly, that's probably the least interesting implication of a constructive proof that p=np.
The entire field of cryptography is based around the idea of problems easy to solve with a short piece of information but hard to solve without it. If P=NP (and we have a constructive proof with an algorithm where the constants & degree aren't rediculous), the entire field of cryptography would collapse. Only 1-time pad's would be safe.
Polynomial doesn't mean practical. In practice, O(n^100) is not an improvement over O(2^n).
Also, we could imagine an algorithm that takes O(2^n) operation to verify and O(100^n) to find a solution. Both are exponential time (not NP), but the difference ensures that you can make it both safe and fast enough for use. I don't know if we could build such an algorithm if we had constructive P=NP though.
It should possible in principle to create a "printer" in Life that constructs a rectangular region filled with repeated stable objects (like blocks) or nothing, or some dithered density. If you are ok that it could never reach better than 50% density, you could encode your arbitrary image into an incoming stream (say, of gliders) that program the printer to make an arbitrary image. Similar to the way Von Neumann's self-reproducing cellular automaton produces itself from a "tape" of cells.
This is basically treating GoL as a one-way function for which you want to search for inputs that produce a desired output. Sounds just like cryptocurrency. Is there a GoL coin yet? I know there are tons of searches for novel structures but couldn't find a crypto in my quick searching.
Recently just discovered Cure Coin which is a crypto based on folding@home units of work. So that made me wonder about it for GoL too...
it may look a bit faint, because they're sparse, but it seems that you could get any sort of image you want by using a repeatable stamped stable state as your "pixel", and then zoom out far enough.
I posted this previously about Andrew Wuensche's and Mike Lesser's gorgeous coffee table book, "The Global Dynamics of Cellular Automata" (I've updated the links here), which uses a "general method for running CA backwards in time to compute a state's predecessors with a direct reverse algorithm":
There's a thing called a "Garden of Eden" configuration that has no predecessors, which is impossible to get to from any other possible state.
For a rule like Life, there are many possible configurations that must have been created by God or somebody with a bitmap editor (or somebody who thinks he's God and uses Mathematica as a bitmap editor, like Stephen Wolfram ;), because it would have been impossible for the Life rule to evolve into those states. For example, with the "Life" rule, no possible configuration of cells could ever evolve into all cells with the value "1".
For a rule that simply sets the cell value to zero, all configurations other than pure zeros are garden of eden states, and they all lead directly into a one step attractor of all zeros which always evolves back into itself, all zeros again and again (the shortest possible attractor loop that leads directly to itself).
There is a way of graphically visualizing that global rule state space, which gives insight into the behavior of the rule and the texture and complexity of its state space!
Andrew Wuensche and Mike Lesser published a gorgeous coffee table book entitled "The Global Dynamics of Cellular Automata" that plots out the possible "Garden of Eden" states and the "Basins of Attraction" they lead into of many different one-dimensional cellular automata like rule 30.
Those are not pictures of 1-d cellular automata rule cell states on a grid themselves, but they are actually graphs of the abstract global state space, showing merging and looping trajectories (but not branching since the rules are deterministic -- time flows from the garden of eden leaf tips around the perimeter into (then around) the basin of attractor loops in the center, merging like springs (GOE) into tributaries into rivers into the ocean (BOA)).
The rest of the book is an atlas of all possible 1-d rules of a particular rule numbering system (like rule 30, etc), and the last image is the legend.
He developed a technique of computing and plotting the topology network of all possible states a CA can get into -- tips are "garden of eden" states that no other states can lead to, and loops are "basins of attraction".
Here is the illustration of "rule 30" from page 144 (the legend explaining it is the last photo in the above album). [I am presuming it's using the same rule numbering system as Wolfram but I'm not sure -- EDIT: I visually checked the "space time pattern from a singleton seed" thumbnail against the illustration in the article, and yes it matches rule 30!]
"The Global Dynamics of Cellular Automata introduces a powerful new perspective for the study of discrete dynamical systems. After first looking at the unique trajectory of a system's future, an algoritm is presented that directly computes the multiple merging trajectories of the systems past. A given cellular automaton will "crystallize" state space into a set of basins of attraction that typically have a topology of trees rooted on attractor cycles. Portraits of these objects are made accessible through computer generated graphics. The "Atlas" presents a complete class of such objects, and is inteded , with the accompanying software, as an aid to navigation into the vast reaches of rule behaviour space. The book will appeal to students and researchers interested in cellular automata, complex systems, computational theory, artificial life, neural networks, and aspects of genetics."
"To achieve the global perspective. I devised a general method for running CA backwards in time to compute a state's predecessors with a direct reverse algorithm. So the predecessors of predecessors, and so on, can be computed, revealing the complete subtree including the "leaves," states without predecessors, the so-called “garden-of-Eden" states.
Trajectories must lead to attractors in a finite CA, so a basin of attraction is composed of merging trajectories, trees, rooted on the states making up the attractor cycle with a period of one or more. State-space is organized by the "physics" underlying the dynamic behavior into a number of these basins of attraction, making up the basin of attraction field."
Yeah, Conways compression- any dataset can be encoded into a deterministic game, where upon to restore it is a easy adjustable tradeoff of computation, stored presets and relational operations.
So, the bonus point is to find subsets of relationally related games, that can become the parent.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---
Art imitates life. With coronavirus being the dominate thing on my mind, I found myself wanting to make some art — and also felt drawn to cellular automata.
Here’s something I did this week. It’s a 3D cellular automata made in Metal (Apple’s real-time graphics framework) using a 3D texture and compute shader:
https://www.instagram.com/p/B9nuxwDpF4O/?igshid=1qqdhzlo6b0h
Maybe I’ll write up a post on it if people are interested in the details.