I appreciate your links to further reading, and I'm trying to read the Aurora paper right now but after reading the abstract and the intro (I'm in progress right now), I can't find a case that is uniquely fit/perfect for data historians... I know this is already asking a lot, but would you mind giving me one go-to- use case that really made you think "this is what purpose-built data historian-style databases are good for?".
Every issue mentioned in the abstract/intro (which are meant to motivate the paper) seems like it can be solved as an add-on to existing application databases (albeit with their most recent developments/capabilities in mind). The very description of HADP vs DAHP systems seems silly, because it's just a question of write load, and that's fundamentally only solved with batching and efficient IO, or if you give up durability, it doesn't seem inherent to the data model. There's also assertions like:
> Moreover, performance is typically poor because middleware must poll for data values that triggers and alerters depend on
But like, postgres though, you're free to define a better/more efficient LISTEN/SUBSCRIBE based trigger mechanism, for example, you can highly optimized code right in the DB... Thinking of some of the cases called out in the paper here's what I think in my head:
- Change tracking vs only-current-value -> just record changes/events, as far as tables getting super big, partitioning helps this (timescaledb does this)
- Backfilling @ request time -> an postgres extension could do this
- Alerting -> postgres does have customizable functions/procedures as well as LISTEN/SUBSCRIBE. The paper is right (?) about TRIGGERs not scaling then this might be the most reasonable point.
- Approximate query answering is possible with postgres with stuff like HyperLogLog, but the paper is certainly right in that it is not implemented by default.
Maybe I'm mistaking the extensibility of postgres for the redundancy of the paradigm, akin to thinking something like "lisp is multi-paradigm so why would I use Haskell for it's enhanced inference/safety".
I'm still reading the paper so maybe by the end of it it will dawn on me.
So Aurora isn't a historian, but is a complex event processing system. It's an entirely different beast that solves very specific problems around high-speed queries that could theoretically require scanning through all data stored historically for queries.
I'm not a huge fan of historians (I've spent too much of my career working with them), but I can definitely tell you where they make sense. The scenario is this:
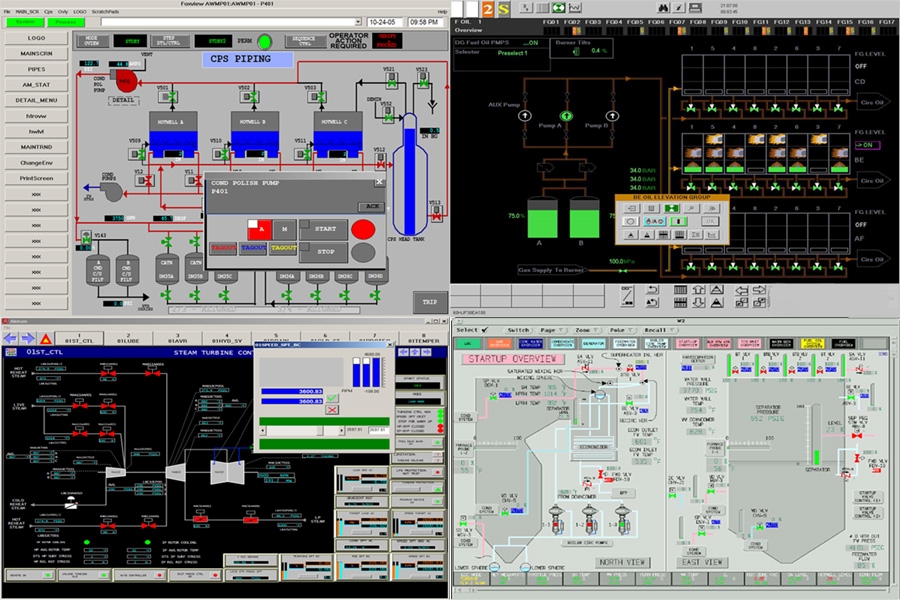
Imagine you have a large facility with thousands of machines, each with a programmable logic chip for controls and monitoring. These machines create lots of data and so often employ data reduction semantics by reducing data to on-change rather than sampling sensors at thousands of hertz. A single machine may have dozens or hundreds of variables to track. These tags might be hierarchical: Machine 1, subsystem 5, variable b. If you say there's 100,000 total tags to track in the facility, and they're on average sampled at 10hz, you need a system capable of writing a million durable timestamped values per second. Now that's child's play for, say, google, but if you're a manufacturer, you can't afford to spend massive amounts of money on cloud systems, and usually want to do this all on a single server on the factory floor because you need realtime monitoring that can display the current value in time for every single tag. ( https://www.ws-corp.com/LiveEditor/images/SLIDES/10/3.jpg ). Ideally, in a single node scenario, you want compression. It's not uncommon to store 100 billion timestamped values per day and keep them for a year or more for audit purposes is something goes wrong. Today, for the sake of predictive maintenance, data retention policies of up to 10 years are becoming more common.
So what would you sacrifice to be able to do efficient realtime monitoring and ingestion of millions of data points per second? You can't use queueing semantics to protect an RDBMS because logging can't take more than a 10th of a second per point. If you think about the use case, what you'd sacrifice is transactional queries and row-level joins, because you just don't need them. At the same time, this data is really sparse when you look at it from a table's perspective, so you'll want something like a column store to underly the data storage.
So what we do is throw out transactional guarantees, choose a storage system that is good at compression (roll-ups in some historians will store a formula approximating the data instead of raw data itself over a window), and prioritize speed of point retrieval for most recent "hot data" by caching it in-memory.
You can of course extend Postgres to achieve many of these things, but having done it myself, in practice it's sub-optimal in the exact same way that using bubble sort for all your programmatic sorting needs is sub-optimal.
One thing you might want to keep in mind is that many of the people involved in Aurora are the authors of Postgres. They're not arguing you can't do things in Postgres, they're arguing that in practice the RDBMS's guarantees are theoretically incompatible with high performance in the area of Complex Event Processing, because alignment between different simple events (recorded as rows in a database) can drift so far that memory requirements become prohibitive if you don't use a stream-processing architecture.
Also keep in mind that Aurora is from 2002 and many of the ideas have been implemented elsewhere over time. The great thing about Postgres is that it's perfect scaffolding on which you can build other stuff.
{kind=link}
Every issue mentioned in the abstract/intro (which are meant to motivate the paper) seems like it can be solved as an add-on to existing application databases (albeit with their most recent developments/capabilities in mind). The very description of HADP vs DAHP systems seems silly, because it's just a question of write load, and that's fundamentally only solved with batching and efficient IO, or if you give up durability, it doesn't seem inherent to the data model. There's also assertions like:
> Moreover, performance is typically poor because middleware must poll for data values that triggers and alerters depend on
But like, postgres though, you're free to define a better/more efficient LISTEN/SUBSCRIBE based trigger mechanism, for example, you can highly optimized code right in the DB... Thinking of some of the cases called out in the paper here's what I think in my head:
- Change tracking vs only-current-value -> just record changes/events, as far as tables getting super big, partitioning helps this (timescaledb does this)
- Backfilling @ request time -> an postgres extension could do this
- Alerting -> postgres does have customizable functions/procedures as well as LISTEN/SUBSCRIBE. The paper is right (?) about TRIGGERs not scaling then this might be the most reasonable point.
- Approximate query answering is possible with postgres with stuff like HyperLogLog, but the paper is certainly right in that it is not implemented by default.
Maybe I'm mistaking the extensibility of postgres for the redundancy of the paradigm, akin to thinking something like "lisp is multi-paradigm so why would I use Haskell for it's enhanced inference/safety".
I'm still reading the paper so maybe by the end of it it will dawn on me.