I got decently far in my implementation, but probably wouldn't suggest you use this. The actual guide is pretty sloppily written and doesn't outline all that much, along with not explicitly saying what you have to define at each step. It doesn't define what the different cases of the mal Lisp value type should be, for example, or when to implement pretty much all of the "optional" extensions it mentions in the first or second chapter. Most of the forms in each chapter get a sentence explanation of what they do, at most, and I hit several snags where I read an explanation and thought I implemented it correctly, only to find out there was something subtly wrong with the obvious implementation.
Also, writing a Lisp in a purely functional language isn't the best :X Things like by-reference function environments and atoms are hard to implement if you're not Haskell, at least if you try in the method that the guide outlines...
There is a similar project called "Build Your Own Lisp"[0] (BYOL), which is a book that walks one through making a Lisp in C. Has anybody here done BYOL? How does it compare to MAL? If you had to choose one to learn how to create a Lisp, which would you choose?
BYOL is targeted at implementing Lisp in C and focuses on learning C. There is a fair bit more hand-holding and example code in C for most of the steps than in the mal guide. BYOL is more polished and written in the form of a short book whereas the mal guide intentionally tries to be more concise and informal in style. I would read through the first couple of sections of both and decide based on your own goals and preferences.
Actually you might like stage0 http://git.savannah.nongnu.org/cgit/stage0.git/
It literally goes from a 280byte hex monitor all the way through a compacting garbage collected lisp and FORTH
Without the assumption that any other software exists
I looked at BYOL a while ago, but was turned off by the fact that the author wants you to use his parser. I don't know why, but I didn't like that. I feel like there's value in using a pre-existing, widely-used parser like yacc/lex, for no other reason than that it already exist and is widely used.
Oh man, that's a bummer. I think one of the great joys in constructing your own compiler or interpreter is making your own lexer and parser. Doesn't using a pre-made lexer/parser kind of defeat the purpose of making your own compiler/interpreter?
Make a very decent interpreter for a language that is good for writing compilers (without a question, a Lisp of some sorts, of course, ha).
Then, write the compiler in that language.
The compiler walks the code just like the interpreter, but instead of interpreting, it spits out a translation.
Spitting out some kind of translation into something isn't a very high bar; the difficulties are all in optimization: things like analyzing lexical scopes for the presence of closures which escape, so as to be able to stack-allocate environments that aren't captured by closures. Plus all those other difficult things: like turning a program into a graph of basic blocks and doing flow analysis; register allocation, selection of instructions for a myriad target machines, debugging suport, and so on. Any of these requirements can be excluded from a compiler, yet it's still a compiler.
The "Lisp in 500 lines of C" (plus accopmanying .lisp) file implemented a compiler. The complete source is hard to find, but here is a derivative project: https://github.com/jackpal/lisp5000
A chunk of init500.lisp implements compilation to C. Search the file for terms like "compile" and also "deftransform".
If you've ever written a macro, you've written a piece of a compiler. Macros take an input syntax tree and spit out a new one. Many actions traditionally associated with a compiler (by Lisp-unaware computer scientists) can be done by macros or in the macro expander. Basic compiling is a lot like macro expansion. It can actually be Lisp-to-Lisp even; the transformers can spit out a Lisp data structure representing a target language. (Heck GCC spits out a Lisp-like data structure for intermediate code. Of course; it was originally a project started by Stallman.)
I have that book, though I haven't looked at it in years. I found it intractable then. I've been using clojure in the interim and feel like I've learned quite a bit, so maybe I should go back and look again.
Not to toot my own horn too much, but I have also written a tutorial[0] aimed at building a Lisp in OCaml. I wrote it to teach as much as learn how to go about it.
I am curious why is hackernews always so happy and obsessed with lisp, there is almost daily a lisp post on the frontpage. I dont really care/mind but I am just curious as why people love lisp so much. The only thing that I notice about Lisp are the bracket jokes and memes.
Paul Graham and Robert Morris built one of the first web applications (that's a PG claim, btw) that allowed users to build their own, separate websites that had shopping carts, custom UI, etc.
They wrote the app in Common Lisp and claimed that it was their secret weapon which allowed them to iterate faster and stay ahead of their competition. They ended up selling their company (ViaWeb) to Yahoo for $50 million (IIRC).
PG also authored two books on Lisp, and HN is written in Arc (a Lisp built on top of Racket).
Around 2005 I was doing a lot of Lisp programming and I was really interested in what PG had to say. He was writing a lot of essays then and giving lots of talks, etc.
Unfortunately, I don't get the opportunity to use Lisp as much as I used to, but I'm doing a lot of Python and even played around with Hy (Lisp on top of Python). So I'm interested in Lisp as I find it to be an incredibly powerful language that is really fun to use.
After being a user of languages for a long time, writing my own LISP was the experience of leaving Platons cave and seeing what the thing I use daily really is made of. What is "if"? What is a boolean, a variable, a function?
It's a beautiful thing. I wish I would never have to climb down into the cave (languages with more advanced parsers) again.
Interesting enough, the primitive versions of LISP that aren't high-performance (i.e. advanced compilers) could probably be done by hand in hardware where the whole thing was bootstrapped up with LISP-only tech. The LISP would start/stop at the abstract, state machines or RTL of the bootstrapped version.
EDIT: Good luck on making it through the hurricane. Feel for yall out there.
Learning assembly is great, and every programmer should dive into at least a simpler version of it, but it's not exactly the best way to learn how your high-level language is implementing tail-call optimization.
Which you can code in a convenient way by using Lisp and Lisp macros to generate the <insert target CPU> machine language output using <insert target CPU> opcodes.
> Every time someone says this there seem to be nothing but haters.
Because it's not completely true. If a CPU is microcoded, then it's accurate to say "assembly is interpreted" because every instruction is effectively an address into a lookup table of microinstructions. But in a non-microcoded (e.g. purely RISC) CPU, the bits of the instruction word are effectively enable and data lines to a bunch of hardware logic gates and flip-flops, which cause register transfers and arithmetic operations to happen. In this case, the ones and zeros in the instruction word are voltage levels on logic gates. Calling the latter "interpretation" is a stretch.
To be fair, there aren't many pure RISC implementations around these days. Most everything has some degree of microcode involved, so to that extent you're right.
It's interpreted because the instructions are fetched one by one. A piano roll is intepreted, even though its holes just activate keys with a "horizontal encoding". It is interpreted because it moves through the piano, and a little piece of it activates a behavior any one time, without leaving a permanent record.
Not only is machine code interpreted, the so-called "asynchronous interrupts" are just periodically polled for in between the fetching, decoding and executing.
I'll use x86-32 for elaboration [1]. When the CPU sees the byte sequence 0xB8 0x90 0x41 0x5A 0x7B, it has to interpet what those bytes mean. It sees the 0xB8, so then it knows that you are loading the EAX register with an immedate value. The next four bytes (0x90, 0x41, 0x5A, 0x7B) are read and stored into EAX (as 0x7B5A4190, because Intel is little endian).
That is the case for all instructions. Each one is interpreted by the CPU. And for modern CPUs, even translated into an internal format that is futher interpreted.
[1] Sans power right now. Using my cellphone as a hot-spot and my iPad as a laptop. The aftermath of hurricanes is brutal in Florida.
Gotcha, but then (unless I'm misunderstanding) one of these interpreters is not like the other. Namely, assembly 'interpretation' happens on bare metal. Were you previously suggesting that understanding a lisp interpreter will help in understanding CPU architecture?
(Good luck recovering from the hurricane! Keep your head down!)
I was replying more to jospar's post about learning what an 'if' was, what a 'boolean' was, etc. What's an 'if'? Ultimately it's a comparison of two numbers and a transfer of control based upon said comparison. Some architectures that's one instruction, some two.
Lisps have properties that are not so common in other languages:
- Homoiconicity: Code and data are the same (s-expressions)
- Lisp code is basically the AST in itself
- It's trivial to implement lisp in lisp (eval)
- Continuations (call/cc)
- Macros
- etc...
It's a truly fascinating language.
I never really did any Lisp coding outside some university projects and I still obsess and read about Scheme all the time.
>I am just curious as why people love lisp so much.
Lisp is addictive, like a hard drug.
Lisp is the original "programmable programming language".
Experienced programmers with no previous knowledge of Lisp should relish (or doubt in disbelief) at the features provided.
Lisp, at least Common Lisp (but other Lisp dialects as well) might claim to be the most powerful and versatile programming language (and environment) available.
CL can run pretty fast. At the same speed than Java on the oracle JVM, and if some tricks are applied it should match C and Fortran speed under certain conditions. CL code is extremely portable.
Lisp has been used for very high level tasks (AI, etc) and for low level tasks (operating systems for Lisp machines).
Lisp is one of those languages that, once I learned it (Clojure in my case), I started wondering why every language wasn't more like it. Once you get used to the parentheses and whatnot, it's actually an incredibly beautiful language that gives you the ability to augment the language without waiting for updates via its elegant macro system.
In struct MalVal[0], the values f0 through f20, where each holds a pointer-to-functions of the corresponding arity, live in a big (multifacted?) union. Using arg_cnt, the switch assigns func to the appropriate value in mv->val using the appropriate cast.
For example, when arg_cnt is 2, mv->val.f2 receives func converted to void * (* )(void* , void* ), that is, pointer to a function that accepts two parameters of type pointer-to-void and returns pointer-to-void. [Weird spacing to effectively escape the asterisks that would otherwise be treated as italicizing markup.]
C permits conversion between pointer-to-function of one type to pointer-to-function of another type. The inverse is also defined, and the resulting pointer will compare equal to the original. However, calling a function through a pointer-to-function where the types do not match invokes undefined behavior.
This could be made massively less ugly and more readable by typedef'ing the function pointer types by the way. Then one could just write:
case 13: mv->val.f13 = (F13)func; break;
As a C programmer I got to say people in general don't use typedef for function pointer types often enough. The types are so ugly and verbose, they should be typedef'ed by default.
I think the primary argument that I've heard against typedefing function pointers is you can end up obfuscating what is happening and end up making the code less readable/harder to maintain in the future.
This code could take advantage of the fact that the type is a union.
One can bend the rules of prim-and-proper well-defined ISO C just a little bit and assign to the simplest function pointer, taking advantage of all function pointers having the same representation on every machine known to mortal hacker, and all being overlaid by the union. Thus all the cases collapse down to this:
mv->val.u.f0 = (void (*)(void)) func;
done. Now if this is 13 arguments, then strictly speaking, accessing mv->val.uf13 is not well-defined behavior. That's only going to be problem when it actually doesn't work, though. A big problem, then. :)
I look forwards to your pull request! One challenge you'll run into is that (as I recall) the Boehm GC linkage no longer works with newer versions of Boehm.
These functions are only used from within C code; they are not the basis for any intrinsic functions. The call to each of these functions knows exactly the type of function it wants to make.
There is a notation in the naming.
Firstly, the leading 'f' denotes functions with an environment value, whereas 'n' denotes non-environment functions. Then there is a number indicating the number of arguments. Then an optional letter which is 'o' if the function has optional arguments, or 'v' if it is variadic. Both can be present in which case we have 'ov.
Thus for example func_n2ov(some_c_function, 1) will create a variadic function with 2 fixed arguments, of which 1 is required (so one optional). some_c_function has to have the type signature val (* )(val, val, varg). No casting is required because func_n2ov just assigns this to the correct union member. If we pass a function with an incorrect signature, we get a C compile error.
The func_n2ov constructor is used when registering the unique function in eval.c:
We intern the string "unique" in the user package ("usr"), and use that symbol to register a function createdy by hoisting the C function unique into the Lisp domain with func_n2ov.
I wrote TXR in a way that is easy to understand and maintain. It is only implemented in C, though. If you want to study how to make a Lisp interpreter in C. Yet, it is production code for real work.
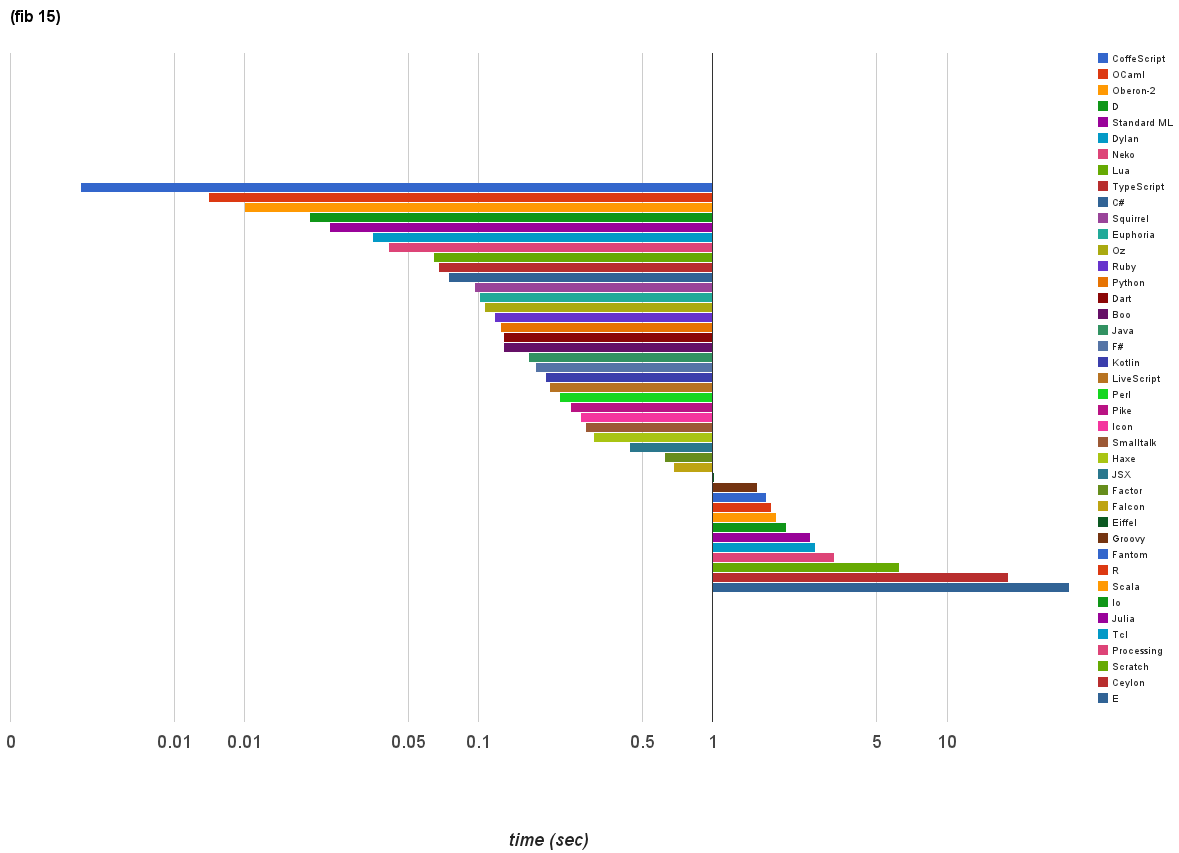
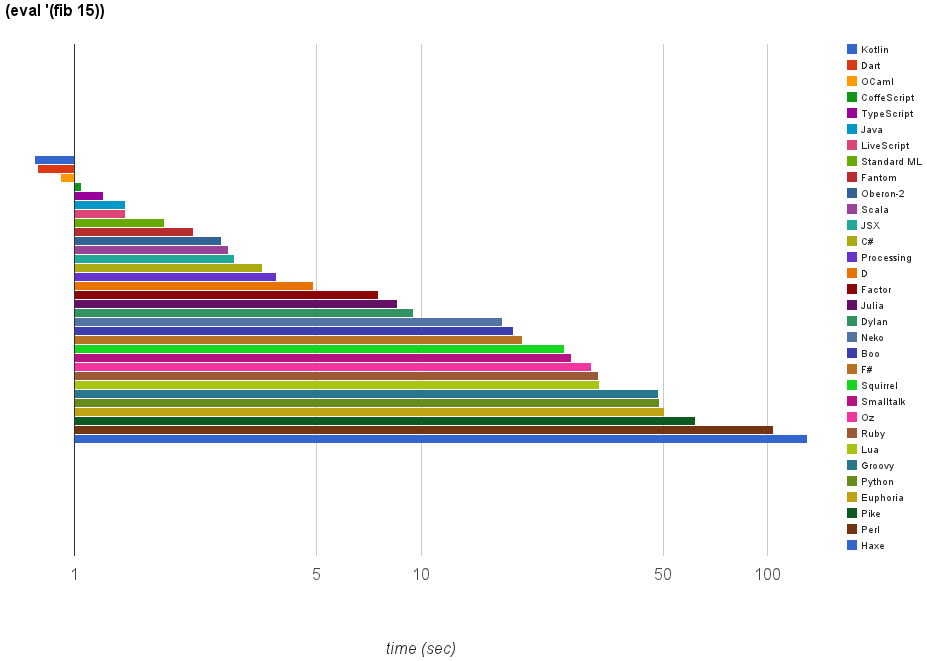
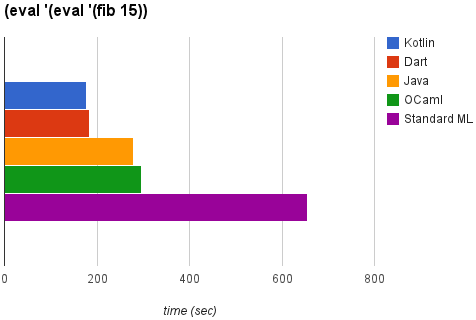
I tried finding the lines of code in each language with cloc. C/C++ Header contains a sum of C and CPP header files. Python has been used across different language dirs as wrapper script or so, otherwise, it's own implementation is probably 1350 lines at max. This would also probably include bugs in cloc.
Every implementation has a stats target that gives byte counts, LOCs, and comments that is specific to that implementation. I.e. from the top-level you can run the following to get stats for every language:
The steps and main files are the same for every implementation (that's part of the requirements for merging into the main tree). Some implementations have additional files like readline, utility routines, etc. But for the most part the general structure and file divisions are very similar.
Implementation size is hard to compare accurately across languages (bytes? lines of code? exclude comments? excluding leading spaces?). Also, the mal implementations were created by many different people so individual style plays a large role in concision/verbosity.
However, that being said, the following implementations are "smallish" (in both lines of code and bytes): mal itself (self-hosted), Clojure, factor, Perl 6, Ruby. The following are "largish": Awk, PL-pgSQL, C, PL-SQL, Chuck, Swift 2, Ada.
OCaml is in the "smallest" third of the implementations.
It started with the question "Could you implement a Lisp using just GNU Make macros"? (Hint: Yes) Bit of trivia: Mal originally stood for MAke-Lisp. Conveniently the acronym didn't need to be changed for "Make-A-Lisp"
It then grew into a personal learning tool for me for learning new languages. As I implemented more languages, I refactored the structure to make it more portable and incremental. At some point I realized that it might be an interesting learning tool for others so I wrote an early version of the guide and had a friend work through it and give feedback. He liked it enough that he immediately did a second implementation.
At some point the project got some twitter/HN attention and other people began contributing implementations and feedback for the guide.
Mal also serves as programming language "Rosetta Stone". A bit like rosettacode.org but using a full working project.
While we're at it, why don't we replace high school math tests with one question: "Solve the Riemann hypothesis". We can replace the physics curriculum with "Unify quantum mechanics with general relativity", and throw out computing courses in favour of "Prove whether or not P = NP".
It's important to re-do things which others have already worked out, in order to reach a greater understanding :)
I learned how to implement Lisp by reading the source code for multiple compilers. Started with Franz Lisp, then KCL and CMUCL. I don't feel that a toy interpreter is going to teach the same things.
Perhaps you could write up the process you followed, in the form of blog post or something, so that you can pass on the knowledge. I, for one, would love a guided tour through those implementations to see which parts are worth studying to understand how an established Lisp is built.
everyone learns in different ways, don't be too attached to your own perspective. we all interpret the world through different lenses and need to learn through the expressions of different methodologies. some people benefit heavily by implementing something themselves and not just reading through something someone else wrote. some people feed off of that practical and robust experience of implementation in order to get a proper context for how things actually work established in their head. concrete examples are more helpful than you might think to people who aren't as capable of abstract thought and logical analysis of something from its constituent parts
Your approach is 100% valid, but it can't hurt to start making a really small lisp. Of course the implementation strategies of a "MAL" lisp and a Real Lisp are entirely different.
{kind=link}
{kind=link}
{kind=link}
Also, writing a Lisp in a purely functional language isn't the best :X Things like by-reference function environments and atoms are hard to implement if you're not Haskell, at least if you try in the method that the guide outlines...