There's a lot of misunderstanding about self-driving. Mostly because nobody is publishing much.
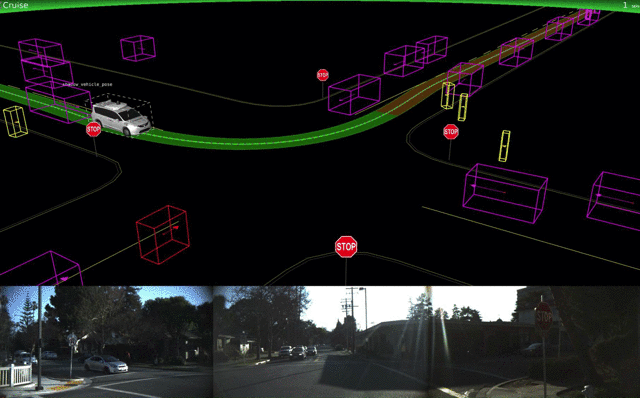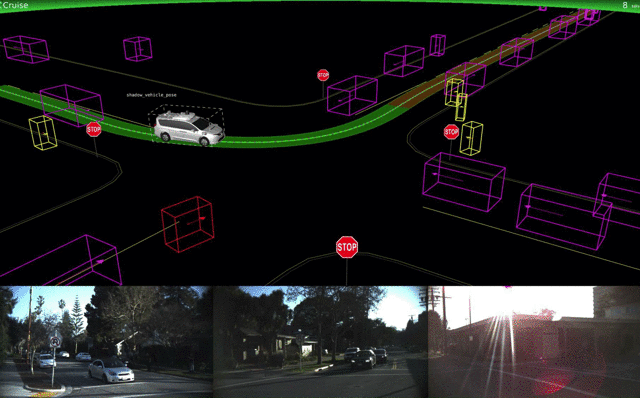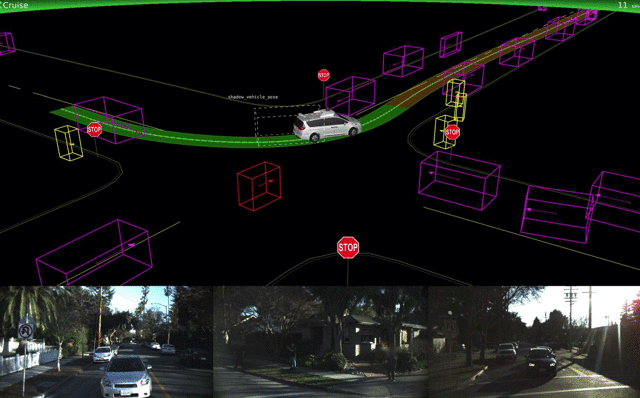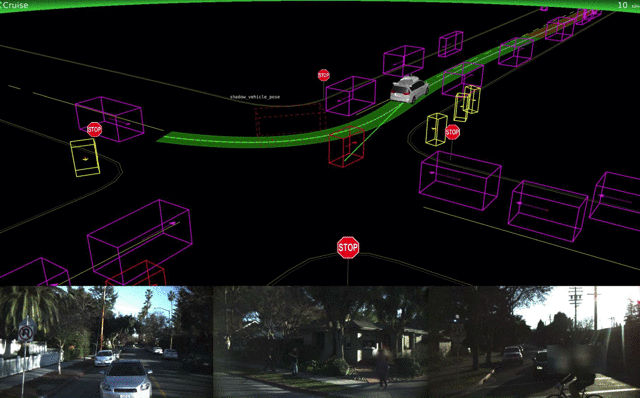
If you want to do it right, you start with geometry. The first step is capturing range imagery and grinding it down to a 3D model of the world. This tells you where you physically can go. That's where we were at the DARPA Grand Challenge over a decade ago.
Then comes moving object popout. What out there isn't a stationary obstacle? That comes from processing multiple frames and range rate data from radars. Moving objects have to be tracked.
Only then does object recognition come into play. Moving objects should be classified if possible, and fixed objects of special interest (signs, barricades, etc.) identified. Not all objects will be identified, but that's OK. If it can't be identified and it's moving, you have to assume the worst case - it's vulnerable and it doesn't follow the road rules. This will force a slowdown and careful maneuvering around the unknown object. (See Chris Urmson's SXSW video of their vehicle encountering someone in a powered wheelchair chasing a duck with a broom.)
Predicting the behavior of moving objects is a big part of handling heavy traffic. That's what Google is working hard on now.
Machine learning is a part of this, but not the whole thing. You can't really trust machine learning; it's a statistical method and sometimes it will be totally wrong. You can trust geometry.
If you want to do it wrong, you start out with lane keeping and smart cruise control, tack on recognition of common objects, throw in some machine learning and hope for the best. This produced the Tesla self-crashing car, noted for running into unusual obstacles which partially block the lane and for trusting lane markings way too much. Look closely at the videos from Tesla and Cruise, slowing them down to real time. They speed them up so you can't easily see how bad the object recognition is.
> If you want to do it wrong, you start out with lane keeping...recognition of common objects...some machine learning....hope for the best
Thank you! Can I ask why the self-driving car programs like the 3-semester Udacity one deliberately focus on going about it the wrong way ? Why spend 1 whole semester on lane detection using trivia like OpenCV, 1 whole semester on object classification using CNNs with Keras, spending so much time on combining lidar & radar data using Kalman filters for moving object tracking .... surely all of these are peripheral issues and the wrong way to go about the business. Then why ? Is it all one big clueless scam ?
To be fair, I am enjoying the course very much as a student. But it's becoming clear from talking to colleagues in the autonomous car industry that what is being taught is not the real deal. This isn't what happens in production, so to speak.
As a Udactiy SDC student finishing up the program without much real insight into the industry, the program seems very much to me like an entry-level overview of topics you're likely to encounter in this field: computer vision, machine/deep learning, path-finding, sensors, and some basic system integration.
By the end, you'll have a few toy projects and a very basic ability to converse about or study more deeply these topics. Maybe they should have spent a little more time on maps and SLAM instead of other stuff, but hey, it's their first version anyway; I'm sure they'll iterate (as they already have somewhat in response to feedback). They did kind of admit in the CV introduction (lane finding) that this was kind of a super simple, satisfying project to start with. I feel like they often touch on topics acknowledging they have more of a historical relevance and are no longer state-of-the-art tools.
(Edit: I should also note: while I have criticisms of the program, overall I'm very happy that I took it. I'm sure some people are better at seeking out specifically what information is relevant to dig deeper into, but I really appreciate the broad overview kind of pointing me in the right direction. Since starting the program I've amassed quite a list of resources to dig deeper into, and hope to eventually find work in this or related field)
All those subjects are useful. Some version of all those things will appear in the good systems. But it's the difference between building the flight control system for a toy drone and the flight control system for a Boeing 797. You need the "failure is not an option" attitude of aerospace. You need fault tree analysis. What if sensors disagree? What if a sensor is misaligned because someone bumped the vehicle while it was parked? You need enough of an organization to have people working through all those situations. You don't get to blame the user for your mistakes. A "minimum viable product" will kill.
Self-driving is something many people in software haven't seen much - software that isn't feature-oriented. As someone from Google pointed out, the output is just two numbers.
Isn't the practical reality that any course like that will address the theory and essentially deal with more or less toy problems? It would be hard to get into cutting edge research in an online course.
I'm not sure learning about natural language processing or image classification would be all that different--although those problems are arguably better understood and more bounded.
Even a site reliability engineering course isn't really going to give you deep insights into what, say, Google does on a day-to-day basis.
>Even a site reliability engineering course isn't really going to give you deep insights into what, say, Google does on a day-to-day basis.
I think this really gets to the core of the issue. There aren't many courses that will accurately reflect the actual state of the art in any field. Sometimes, graduate courses with a small scope and a relevant professor taught in person can partially address the state of the art, but an online course about "how to self driving car" is not that.
Lectures, tech talks, blogs, random experts in relevant subreddits, but yes, an online course is not going to give more than the fundamentals and some advanced, but already well understood examples.
Thank you! It's so good to see hype free discussion of this stuff.
I would also add that using simulations to test (or train) robots is also not new, and has significant limitations. Robotics has been using simulation since before the Grand Challenge, but what we find is that simulations make simplifying assumptions that don't bear out in real life: simulated sensors are more idealized than in real life, object recognition is idealized, actuators are idealized. But that makes it hard to apply any learnings to the real world, where sensors hallucinate and actuators lie all the time.
And yeah, we _could_ be fuzzing the simulation and adding failure modes, but not many people do. It's hard to simulate these kinds of defects in a usefully realistic way.
I work in robotics, and I meet people with this attitude all the time. This kind of thinking is OK when your robot is a small desktop toy, or a humanoid robot moving at 1 cm/second, but this approach will not work if your robots can damage expensive equipment or kill people.
The key thing to understand is that your simulator is not a fixed product provided by a third-party. It grows organically with your codebase. So any time you encounter a bug in the real word, you have a three step process:
- Create a test case to reproduce your bug in the simulation. This may involve updating your simulator to simulate the new physical properties we care about (such as new failure modes or new types of the sensor noise)
- Fix your code, and make sure your test case passes
- Add the test case to automatic testing suite and keep it there *forever*. this is the most important part.
For an SDC company, the test suite is almost as important as the code itself. The time spent on writing testing code and test cases could be actually more than time spent writing the driving code itself.
Unfortunately, many academic courses use an opposite approach: they use pre-made simulators, and do not modify them at all. This gives students the wrong expectation that you can find a simulator which can just simulate everything perfectly out-of-the-box; when this (predictably) fails, they become disappointed in the whole simulation idea.
One of the things that seems to be going on is that, after relatively limited visible progress for a long time, the ability to collect and analyze large datasets suddenly produced fairly striking results. And this in turn has led to a lot of thinking along the lines of "We just need to collect more data and crunch the numbers a bit better."
As you suggest, for at least some classes of problems, we'll find that this approach will asymptotically approach some level of "good" that turns out to not actually be good enough. And the ways to get beyond that will be hard and may not be obvious.
Really well-written and engaging article. It seems the main point of an article like this from Google's perspective is gaining the public's trust. I'm sure most people are worried about the edge-cases that are so hard to run into in the real world, but are so important to get right. This is Google saying "we may not see that edge-case exactly, but we know when it could happen and simulate the situation a million times to make sure we get it right if we ever see it again."
I occassionally come across construction that is marked in an unusual way - at 65 miles an hour when the speed limit is 75. Also, when they are changing freeways and restriping them (leaving the original old faded lanes and before new lines go up) sometimes it's confusing to me and the traffic is flowing at 80 miles an hour, IIRC this was happening on 880 for a while about 10 years back.
If the AI is confused by a roundabout as described I wonder how they handle that or if this is something that only fools me because I am only using visual sensors.
Aren't those examples in which it'd be fine for it to be confused? That confusion shouldn't lead to any dangerous situations, just a different speed than other cars.
It would also be interesting to know whether Waymo factors in other cars' behavior. If everyone is going 80 while the speed limit is 65, will it factor that in and go 80 or keep with the speed limit?
I don't know what a good answer is, my recollection of those examples is no one else is slowing down so I need to go the same speed in order to not be rear ended and hope the car in front of me knows what they are doing. This feels pretty unsatisfactory.
The speed limit is kind of interesting, occassionally see someone go the speed limit on I-5 but it's hard to maintain because there's always an eighteen wheeler going slower than that, and then it hits a hill, and then there's a cascade reaction where the slow lane hits 45-50 for an extended period but the fast lane is going 75-95, though just being patient and waiting in the slow lane isn't a big deal for a autodriving car, or 280 between San Francisco and San Jose with sections where it appears almost everyone is going 85 miles per hour (not sure why CHP doesn't just camp out there). I see Teslas in both these places but I've never seen a Waymo.
A slower speed is dangerous to everyone. One car slows down and everyone else needs to get around them. That results in people who would otherwise be content to flow with traffic making aggressive moves to pass the obstruction. These actions catches some people in the other lanes unaware and some of them insensitively hit their brakes (kind of like the people who brake for curves at low speed because "it's what you do") which exacerbates the problem.
Now add in a poorly marked road dense traffic and construction. Other drivers (as a ground) don't really have the spare attention to allocate to the fallout of someone who's slowing down.
edit: This is backed up by traffic studies When everyone is driving the same speed things are safer because there's less "friction" (I think that's the correct term) between traffic elements.
"Avoid highway braking!" was drilled into us in drivers ed.
Too slow was equal to too fast during drivers ed.
We had a trailer with a simulator screen and a projector, and about 10 or so fake wheels, brakes and accelerator. He would stop the reel and quiz us about the scene (kid on bike about to cross road; kid hidden by truck. ) The instructor had a print out of our actions. Pretty sophisticated for the mid '70s.
Both of those situations are one where policy could be changed to solve the problem with relative ease. Transportation construction crews would actively put up markers and other signs to make routes clear to self driving vehicles. A side effect would be that it would probably be more clear to human drivers as well.
Swarm mode can still happen with clear markings. I assume the vehicles don't have a dedicated swarm mode, more like they try to do lane keeping but the distance and road keeping algorithms override that. If not, a "great" practical joke would be to paint lane markings that run off the side of the road. It's just like any piece of software, you cannot trust any external input, not even road markings.
Now this is doing it right. That's how car companies do it. Big test tracks, and years of test track time, plus simulation and test rigs.
As the article points out, Google has far more autonomous driving miles than everybody else put together. They're on the hard cases, too; not just driving on freeways.
I was surprised to read in the article that they were flummoxed by roundabouts, of all things. And that they were apparently surprised to discover that multi-lane roundabouts even exist at all. Have none of these engineers ever gone on holiday to Europe? If they think a multi-lane roundabout is an advanced case, what will they make of this?
Snow is challenging because the lane markers are obscured by the snow -- human drivers guess at where the lanes should be, or remember where the lanes were yesterday.
Tesla being able to record sensor/map data from human drivers driving through snow will help them mitigate this. On the other hand, electric batteries have less range in cold whether, so I imagine that in the near term electric cars will be less popular in snowy markets versus, say, California.
While I take the point cold weather affects range. Norway, Sweden, Finland and many other cold climates have very high electric car usage. Mostly due to the subsidies, but it appears range isn't a major concern there.
I'm disappointed the article wasn't a bit more skeptical of some of the claims. Certainly the simulation-based testing is a good thing, but stats about how many billions of simulated miles have been driven can create a self-reinforcing delusion if everyone involved isn't careful to remember that the simulations can only work with well-known and expected situations. It sounds like Waymo realizes this and is building a huge library of scenarios to evaluate, but one million simulated miles are not worth a hundred real miles in terms of confidence in the system, and that is not the message this article portrays.
Overall this article does give hints though that autonomous vehicles are truly much further away than anyone wants to admit. The story about being flummoxed by multilane roundabouts is depressing. If they didn't know such things existed then they were incredibly sloppy in their data gathering. If they truly thought scaling from a simple roundabout to a multilane one would be trivial then their staff don't have the right mindset for this problem space.
Also note that all the testing is happening in flat, desert landscapes where there are no weather or lighting challenges. Their pictured model residential street only has stubs of driveways. No houses, no trees. I'm sure they know these are gaps but I worry they underestimate the challenges of adapting to entirely different driving environments. Especially when machine learning is involved and you're simulating 99% of your mileage...
"One million simulated miles are not worth a hundred real miles in terms of confidence in the system"
I'm wondering why you say that? Wouldn't the more relevant factor be the type of miles, regardless of whether they are simulated or real? For example, 1 mile of simulated "Interesting Scenarios" (Duck on Street, Bicyclist going wrong way, pedestrian running onto road) is likely worth 100,000 miles of normal Freeway driving.
> The story about being flummoxed by multilane roundabouts is depressing
Don't underestimate the bizarre engineering of infrastructure in Texas. Every road and intersection is bespoke, unlike any other you have previously experienced. It is quite difficult to navigate Austin as a human driver, I suspect it makes for a good testing ground for Waymo.
One millions miles of different situations is worth more than 100 miles anywhere. Even your most carefully chosen worst case route won't cover all situations.
To get close you have to pay people to send their kid running between parked cars into the street at just the right moment. Nobody sane will put a real kids into that situation, but the simulation can (should!) have thousands of different variations. The simulation can afford to run all of those situations regularly. Simulation can ensure it is raining when you need it.
You need miles of real driving too, but they are too expensive and unpredictable to rely on for more than a final check.
>
But Peng also presented the position of the traditional automakers. He said that they are trying to do something fundamentally different. Instead of aiming for the full autonomy moon shot, they are trying to add driver-assistance technologies, “make a little money,” and then step forward toward full autonomy. It’s not fair to compare Waymo, which has the resources and corporate freedom to put a $70,000 laser range finder on top of a car, with an automaker like Chevy that might see $40,000 as its price ceiling for mass-market adoption.
> “GM, Ford, Toyota, and others are saying ‘Let me reduce the number of crashes and fatalities and increase safety for the mass market.’ Their target is totally different,” Peng said. “We need to think about the millions of vehicles, not just a few thousand.”
I wonder if an easier task to reduce fatalities is to target impaired driving and develop a detection mechanism that tries to identify whether the driver is impaired. It seems like an easier and more localized problem than building a fully autonomous vehicle.
Someone who saves a huge amount on their car insurance because they own such a vehicle (and therefore should never be subjecting the insurance company to claims caused by their impaired driving) I assume?
People that get convicted of DUIs and want to keep their license. We already have modifications to cars that require people to blow into to start their car, this seems like the logical next step in that.
Fun fact: In tor browser google maps shows the newer imagery, in firefox it's using older images (and also talks german). (Ok, it seems to be tied to the browser language…still…)
I found this to be especially interesting "She spent countless hours going up and down 101 and 280, the highways that lead between San Francisco and Mountain View. Like the rest of the drivers, she came to develop a feel for how the cars performed on the open road. And this came to be seen as an important kind of knowledge within the self-driving program. They developed an intuition about what might be hard for the cars. “Doing some testing on newer software and having a bit of tenure on the team, I began to think about ways that we could potentially challenge the system,” she tells me."
Clearly the progress being made in the area of self-driving cars is undeniable. Seeing the articles and discussions crop up on a daily basis are making me wonder if we are headed for an AI Winter scenario in this area within the next decade or if this is the real deal and we will see self-driving cars at dealerships within 20 years.
This is so far from being my area of expertise. Just one observer's thoughts/questions. Insane how far we have come so quickly, at any rate.
I don't disagree that AI is over-hyped. However, I think the research environment is not as likely to dry up this time.
That is because much of the machine learning research is coming from industry, particularly the mega-corps. And for extremely important disruptive events such as AI, they are willing to drop $$ into collecting a stable of research scientists to not fall behind in this space. So while the AI winter was driven by a drop in academic and government spending on research, I think our present situation is far less likely to result in a similar drying up.
Agreed. As a Google engineer, I think a lot of our AI efforts are "safe" (as in we'll keep investing in them for a long time) because they're already providing substantial business value. For example,
- TTS and speech synthesis have lots of uses in Android (phones, Wear, Auto, etc.)
- Object recognition is very useful for photo search
- Face recognition is also useful for photo search (if you tag people in Google Photos)
- Neural machine translation provides better translation accuracy (for languages which we have enough training data for)
It's possible Google will cut back on some more speculative ML research efforts, but certainly not those four, I would think.
I doubt Google will cut back any time soon, but as a former Google engineer, I find this an entertaining definition of business value ;)
How much money does Google Photos make? Last time I used it, there were no ads in it.
Isn't speech recognition nearly at human levels of comprehension, at least for US English and outside of highly technical jargon? Speech patterns change slowly, so would Android continue to make money if investment in speech R&D were cut back? My guess is yes, it'd be fine.
Does Google Translate make money in some specific, measurable way? I don't mean "well it's neat to have translation links in web search", I mean, would people cut back on the commercial queries that are Google's main source of income if Translate quality stopped improving? I doubt it.
Much of their products are like this. They're products but they aren't businesses. It's very easy to lose sight of the basics of business when inside the Google bubble. The things you mention are not providing business value in the conventional sense of the term because they aren't yielding independent profits. So they're all vulnerable.
That said, vulnerable to what? I think Google is at risk of losing a lot of trust around web search and political and informational search more generally, but commercial queries are probably pretty much impregnable.
But selling disk storage is a very marginal business and few people take huge numbers of photos they value enough to pay for storage of (vs sticking them on Facebook or Instagram which compresses the hell out of them but does it for free). I really doubt this is a significant business for Google.
But this will only compound, no? If people keep using it, the switching "cost" (cognitive/time) increases exponentially and people will near the storage limits.
Speech recognition is still nowhere near human levels of comprehension. I have no speech impediments and speak US English with a neutral accent, yet Android speech recognition makes so many mistakes that it's usually faster to just type.
> I have no speech impediments and speak US English with a neutral accent
FYI: there is no such thing as a "neutral accent" - unless you mean neutral to your locale. I could describe an object as having "neutral temperature", but you'd need to know how hot/cold its environment is before it makes sense.
That's not correct for US English which absolutely does have a neutral accent unrelated to locale. For typical examples listen to nationwide network news broadcasts.
Well, yes, because an accent generally associated with the Northeast and Midwest became "Network Standard." The Wikipedia article on the topic is quite good. https://en.wikipedia.org/wiki/General_American
It's true that this accent generally lacks the strong regionalisms that some other US accents do. But it's mostly still an outgrowth of a general region even if its use is cultivated more widely.
> Isn't speech recognition nearly at human levels of comprehension, at least for US English and outside of highly technical jargon?
Recognition of technical jargon is an easier problem than recognition common speech. Jargons are far more regular and have limited lexical and idiomatic variation, while common speech has a huge number of variations and is constantly innovating new usages. This is evidenced by the fact that the earliest speech recognition systems were only useful in highly restricted domains (medical transcription, phone support tree navigation).
As a fellow google engineer, I'd be curious to know which (public) research you think isn't marketable/valuable.
As you've mentioned, object detection (which is a considerable portion of CV) is marketable. Meta learning (Vizier, "Learning to learn with gradient descent with gradient descent") are incredibly valuable from a business perspective. Model compression is important for neural networks on mobile/embedded devices, etc.
One of the very interesting things about ML being such a corporation driven field is that it's incredible how quickly relatively recent research makes its way into products.
> One of the very interesting things about ML being such a corporation driven field is that it's incredible how quickly relatively recent research makes its way into products.
I think this is just true for really anything that falls purely within the domain of the computational sciences. For a ground breaking drug to hit the market, it takes 10 years of FDA trials, for high speed trains it requires large teams of construction workers only after years of safety work.
In the world of software as it stands today, deploying a new model for something can be virtually instant in some cases, and even in the worst cases, it isn't taking people years to improve a small attribute of their product.
This is kind of what I figured. I get the distinct feeling that any startup that is unable to keep pace (or break new ground) with AI research & development is going to be hurting badly within the next five years. Uber is poaching AI and Robotics talent, read:profs, from Carnegie Mellon for a reason. It is a do-or-die situation it seems.
Great comment. As a nit, I think "poaching" is a bad term. Uber offered to pay these professors what it viewed as what they were worth to it, which happened to be a lot more than what CMU was paying them. The professors accepted of their own free choice. I fail to see why such an action is termed "poaching". We have had enough problems with industry illegally conspiring (see Steve Jobs) to suppress developer pay through "anti-poaching" agreements, that the term "poaching" is long due for retirement in describing situations other than when animals are illegally killed.
Hey there, thanks for the nit. I am kind of a language nerd, so always appreciate a bit of analysis. I see your point "poaching" as a word has had a somewhat problematic historical context attached to it. I guess I used the term relating to it's sub-definition "take or acquire in an unfair or clandestine way."
I found the migration of experts from CMU to Uber fascinating — for two reasons: 1. The geographical proximity in which the acquisition occurred (i.e. a rust belt town with an awesome CS school and a well known Silicon Valley startup on location). 2. The moving from the academy to the private sector of said professors/researchers happened in a way I hadn't seen before. I mean lots of academics work within industry at some point, but this move seemed to carry more weight in the media — maybe because of the institution involved.
Anyway, with that said, lots of the articles and speculation I read about it, for better or worse, painted the acquisition of academics by Uber as a bit unfair. I.e. Uber could and did pay way more than CMU and provided super interesting problems maybe outside the realm of what a professor normally faces in their research, I don't know. It was the "unfair" element portrayed in articles/opinion pieces I based my wording off of. I am in no way suggesting these profs and researchers did anything wrong or did anything but make the right choice for themselves, something we all have to do.
I digress. Word choice noted, problematic history and other associations noted and hopefully I cleared up my choice a bit.
> Seeing the articles and discussions crop up on a daily basis are making me wonder if we are headed for an AI Winter scenario in this area within the next decade or if this is the real deal and we will see self-driving cars at dealerships within 20 years.
It will be either one of those two, if it doesn't happen in the next 20 years I would bet against it happening at all until AGI is a reality, assuming it will ever happen in the first place.
But if it is possible with an incremental change to present day technology I fully expect it to happen and likely a lot faster than those 20 years. The economic incentives are too large to ignore and there are many players wealthy enough to finance such an incremental step.
For a lot of people, true hands-off autonomous driving on limited access divided highways is by itself a huge convenience feature and, potentially, a huge safety feature. And this seems like relatively low hanging fruit. People will pay for this. (And are, in a limited way, on more and more cars today.)
It's not sexy and doesn't fulfill autonomous taxis everywhere fantasies but for the vast majority of people who don't live in or near urban cores it would likely be a significant quality of life improvement.
Self driving cars is based on machine learning which is basically processing massive amounts of past data. This is great for routine situations and it seems Waymo is making good progress covering most of these. However the key weakness is the lack of true intelligence. When anything unusual or unexpected happens, the best it can do is simply safely shutdown and wait for a human to intervene. And the car can't really analyze and understand its environment because that requires intelligence.
It seems a best of both worlds solution would be a new type of job: Data gathering driver. It would be basically like the Google Streetview cars, but with much more sensors and input from the driver. These drivers would be assigned neighborhoods to drive through and note anything unusual or noteworthy. Stop sign is down because of last night's storm? Driver notes this and now all Waymo cars know. Street closed due to construction? All Waymo cars will avoid that street. This type of data requires intelligence to analyze and understand and it would be fed into the Waymo system for all self driving cars to benefit from it. There could be millions of self driving cars and a few thousands of these drivers feeding daily updated data to the system. You could even increase the frequency of the drivers depending on weather conditions. Maybe if there's a storm, the drivers keep driving in a loop hourly instead of once daily.
There arent that many novel scenarios on the road. Sure, Google can't program around the possibility of an airplane falling down on you, but how often does that happen?
It doesn't have to be perfect. Just very good and improving. Some time ago google shared a gif of a wheelchair chasing a duck in the middle of the road. The car didn't understand it, so it just stopped. Good enough for me.
Obviously, they have a lot of work ahead of them, but don't be so pessimistic. Most people drive shitty (myself included), we aren't impossible to improve upon.
Novel scenarios might not be common compared with miles of traffic-following drudgery, but even really bad human drivers deal with novel scenarios on the road more often than they have accidents.
Stopping might be a sensible safety protocol in some situations, but it isn't in others (not to mention the situations where the car may stop too late because it doesn't actually recognise that a novel scenario is about to occur).
So if you want Level 5 driving, and not just a very impressive demo which is safe provided a human watches it attentively enough to take emergency measures and is able to override it when it decides it can't process a situation well enough to proceed, you need the AI to be pretty damn close to perfect in its judgement of how to react to a huge number of edge cases.
Except self driving cars are paying full attention all the time and can react significantly faster. This causes the difference in stopping distance to be dramatic. Remember, humans are basically going to do the same thing for the first 0.25 seconds in any emergency situation and that's the best case.
So, self driving cars can simply be very cautious without seeming to.
I agree that self driving cars' response time can sometimes compensate for lack of general intelligence to anticipate a visible roadside activity developing into a hazard or non-routine situations in which another driver might cut into their lane. But lightning reflexes aren't going to eliminate situations in which buggy, late or nonexistent responses to things an AI hasn't been trained to deal with endanger other road users, especially when said other road users don't have lightning reflexes themselves.
Can you give an actual example? Because, not being able to identify something is not necessarily an issue as long as the car notices something is there and it should not hit it.
EX: I am sure the car had no idea what this was: https://youtu.be/Uj-rK8V-rik?t=26m11s but as long as it can tell it's bigger than a bread box and so it should not to hit it that's enough.
The obvious problem scenario is when unpredictable evasive action puts an autonomous vehicle into the path of other drivers (with human response times). That's when very sharp responses to an uncategorised "obstacle" that's actually a drifting plastic bag or a reflection cause more problems than they solve.
Similarly, instantaneous harsh braking might help an AI save the small child it didn't anticipate might chase the football that flew past moments earlier, but a human capable of grasping that footballs are associated with pedestrians making rash decisions might have braked early and gently enough to not get bumped by the car behind. (If they didn't, they might find their late reaction blamed for the accident and possibly even get prosecuted for driving without due care and attention).
The UK requires every learner driver to sit an exam consisting of identifying CGI "developing hazards" where they're scored on ability to rapidly identify stuff that might happen before they're allowed to do the full driving test. I'm sure a key focus of the teams the article discusses is teaching AI similar cases like gently slowing in the event of a football-shaped object moving near the road (which is likely far from the most difficult or obscure novelty to teach an AI to handle) but the problem space of novelties humans handle by understanding what things might be and how/if they are likely to move isn't small or one there's good reason to believe plays to AI's strengths
(Meta: not sure why you're being downvoted, your contribution seems constructive and on topic to me)
A bag* or child running into a street is not an usual event, also a car is not going to 'evade' into another car. Rare events are the things people don't see across multiple human lifetimes not just something you don't see every month.
Which IMO is what's missing from the debate, unusual events are in terms of ~10+ million miles of training data before these things are in production. They are clearly out there, but I doubt people are going to react well to say someone falling from an overpass onto the road very well either. So, it's that narrow band of really odd but something a person would respond correctly to that's the 'problem'.
PS: Of course the bag might relate to a bug which are likely. But, IMO that's a completely different topic.
> A bag* or child running into a street is not an usual event, also a car is not going to 'evade' into another car
Opting to drive around a (stationary, visible from a distance) bag in an unpredictable manner is literally how Waymo's first "at fault" accident occurred...
The point is that a human has a concept of a "ball" linked to the concept of "children play football" and an understanding that if one sees the former, one should be prepared for the latter to bursts onto the road from behind the partially-obscured roadside. Appropriate action probably involves easing off the accelerator and lightly tapping the brake so the car behind gets a hint that you might have to stop suddenly on if a child emerges from behind a bush. An autonomous car which fails to anticipate even though it's lightning fast at slamming the brakes on is going to get rear ended a lot more.
The neural network of a self driving car might be able to classify small coloured spheres in the vicinity of the roadway as balls, and the AI will certainly have been taught the concept of a human-shaped obstacle moving across the roadway being a "need to stop" situation, but is unlikely to "learn" the association between the two through a few tens of million miles of regular driving, because only a very small proportion of "need to stop" events involve balls (and only a very small number of sightings of spheres moving in the vicinity of the roadway result in "need to stop" events). Of course, you can hard code a machine to respond to ball-shaped objects moving near roads by slowing down and you can construct a huge number of artificial test scenarios involving balls to teach the AI the association between balls and small children, but either of these options involves engineers envisaging the low frequency hazard and teaching it enough permutations of the sensory input for that hazard for it to be able to anticipate it (and there's a balance to be struck, because nobody wants a paranoid AI which drives through the city braking every time it sees something its neural network identifies as a pedestrian or the front of a parked car protruding from a driveway) Suffice to say, we take for granted our ability to know how to react to things like children chasing balls, staggering 4am drunks, tiny puddles the car in front just drove through versus a raging torrents of water through the usually safely navigable ford, sandbags versus shopping bags, vehicles laden down with loads which look like things which are not vehicles, and people frantically gesturing to stop.
> Opting to drive around a (stationary, visible from a distance) bag in an unpredictable manner is literally how Waymo's first "at fault" accident occurred...
"Our car had detected the approaching bus, but predicted that it would yield to us because we were ahead of it.
Our test driver, who had been watching the bus in the mirror, also expected the bus to slow or stop. And we can imagine the bus driver assumed we were going to stay put. Unfortunately, all these assumptions led us to the same spot in the lane at the same time. This type of misunderstanding happens between human drivers on the road every day."
Except, Waymo's is still in the R&D stage where this stuff is being worked out. The bag issue is exactly the kind of thing that will be fixed before production because it's in their training data. It's really the 'unknown unknowns' that will be the problem and they are going to be really odd.
As to the ball case, it does not need to stop just slow if it's possible for a kid to run out fast enough to be a problem. aka on residential streets when it should not be going fast in the first place not a highway where there are no major obstructions. So again, what your describing is in the 'to be dealt with' pile.
I don't mean it's working right now, just they are going to hold off on mass production until it's working.
Anecdotally, Uber has been gathering lots of road quality data from its drivers for years. Not sure if it still holds, but they were recording and uploading accelerometer data for a while.
Recently, Waymo and Lyft launched a self-driving vehicle partnership [0]. With Trump nomination of Derek Kan (Lyft General Manager in Southern California) to serve as Under Secretary of Transportation for Policy [1], would it ease Waymo path towards autonomous car supremacy?
The bike is the red box that crosses the intersection. It doesn't pass behind the car, but by its side. The white wireframe box that "detaches" from the Waymo car is where the cameras are (so what the car actually did). I assume the Waymo car that doesn't stop in the animation is what it should have done instead.
More specifically, the article indicates that the car that doesn't stop is what the software - after changes to fix the original problem - would do now if it encountered the same situation.
Wow, and I must think we're looking to squeeze ~3 more orders of magnitude or more of the reliability before going full driverless ~(1m miles/disengagement)
you can see that 95% of railroad fatalities are classified as either "Trespassers" or "Highway–rail grade crossing". In both of those cases it seems likely that the victims are generally not actually passengers on the train, but rather are people doing something obviously dangerous near railroad tracks.
It's hard to tell.
1. I can't find the 11.3 billion statistic on the Wikipedia page.
2. The stats seem to be per vehicle mile. An average train carries maybe 100 times as many people as a car. If the people on the train were driving cars there'd be 100 times more vehicle miles.
3. Are people who commit suicide by jumping in front of a train counted in the statistics? It seems that if there were no trains, some of those people would find an alternative, so it might be unfair to include them.
If you ignore low speed, low visibility parking lot stuff many people will go their whole lives without being in an accident that they are at least partially responsible for.
A "disengagement" isn't defined as an at-fault accident, though—it's a situation where the AI is unsure what to do, so it reverts to human control.
I think the equivalent for a human driver would be a situation where they're unsure what to do, so they freeze up, or proceed extremely cautiously. I'm not prone to freezing up, but I've definitely encountered situations where I'm uncertain to the point that I proceed with the utmost of caution.
My point was that an at fault accident is an obvious case of a situation a human cannot handle and that it at least tells us something about the rate at which humans "disengage".
Human disengagement isn't easy to define. People don't just say "well this is too confusing, I'm just gonna turn control over to someone else". To define disengagement you need to define a performance minimum. An accident is about the lowest floor you can set to I used that. I would personally say that if you hit the brake on an on ramp while traveling slower than the highway traffic you're "disengaged." People and AI generally travel as fast as they can while maintaining a sufficient safety factor (e.g. people generally don't tailgate each other at triple digit speed and drive slower in snow). If someone's personal safety factor/comfort level requires several minutes of everyone else honking while they wait for a space fit for a semi-truck before pulling their Prius into traffic that may be acceptable to them but if an AI did that I think most people would say that's a failure even if the AI didn't turn control over to a human.
Interesting stuff. I wonder to what extent Google and Tesla could benefit from sharing each others datasets, Tesla has far more real world data than Google at this point in time but Google has the better virtual environment to test in.
And not much lidar data, right? I don't work on this, but I imagine the quality of the data set makes a big difference.
From what I've learned, lidar and radar are typically used for object detection (i.e., avoiding other cars; perhaps augmented with camera data), while cameras are used for things like lane detection and traffic sign detection. If Tesla is trying to solve the same hard problems as everyone else, using weaker equipment, I wouldn't bet on them having a lot of success.
Also, kind of the point of this article is that Waymo has a test area where they can get real data along with the ground truth. That seems much more valuable than unlabeled/random data.
What does that article have to do with self driving car sensor data. It talks about miles driven.
Tesla just put out there an opt-in upload of video data 3 months ago. And even then it is not clear how useful that data is. Especially since a v2 of the autopilot hardware was recently announced.
Interesting. Google's data is more thoroughly tested in simulation, but Tesla might discover more interesting miles by sheer number of cars in their fleet.
The fact that Waymo revealed their "secret" tools for advancing this crucial technology implies that either:
1) They believe no one can quite catch up before they can launch the technology. Since they know several competitors have huge resources and brilliant people, it means they are quite close to launch.
2) These tools have become open secret within the industry, so no harm is done to their competitive position by revealing it to the public, only good PR to be gained perhaps to attract more bright engineers.
I suspect 2) is more likely since several key players have moved around so much in the past couple of years. Relatively high-level knowledge about how autonomous vehicles are being developed at Waymo might have become well-known within the industry by now.
No doubt it's number 2, I've seen quite a few articles about other self driving efforts and the general sentiment I've seen on HN is "Cruise looks like they're far ahead" and "What about Waymo? Did they fall behind?" This seems like Waymo PR is showing off some secrets to re-assert their technical strength.
The strategy of combining simulation with real world data isn't particularly original, nor is the idea of using test tracks. The challenging part is how you do it. This article barely touched on that.
The article is some good colour commentary on what's going on inside Waymo, there's some fresh information here regarding the scale of their operation, but nothing about the fundamentals are any kind of a reveal. The principles of Waymo's development strategy have been well scrutinized throughout the industry. The other thing is that everything that Waymo has publicly revealed has been at least a year old.
There was nothing secret in that article. Everyone is doing it. E.g. BMW won an industry innovation award for their simulation work years ago. Yes, right around the time when Google were still just driving around in a parking lot.
The rate at which high level engineers move around leads me to believe that quite a few companies will arrive at approximately the same level of autonomy at the same time. Thus the marketshare for autonomy providers is probably going to be based on other factors than the actual technical superiority. Waymo will presumably need buyers, many of whom are the type that like IBM Watson style marketing.
Great to see such progress made by Waymo and Co. But as the Murphy's law says, if something might break, it will eventually break. With possibly millions of self driving cars and trillions of unique situations, its inevitable that someone will get hurt. So my question is: what kind of progress is being made to draft a legal framework for situation in which I rode my bike in bike lane and for whatever reason self-driving vehicle struck me. Who do I go after in regards to my pilling up medical expenses? Do I sue driver? The car company? The company who delivered self-driving hardware? The software manufacturer? I get that self-driving cars comes with incredible advantages: less crashes (hopefully), no drink drivers, etc. But a legal framework for such automobiles should be in works as we speak.
Edited: of course Murphy's law; thanks for pointing it out!
Globally, the death toll on roads is about 1 million per year. If autonomous vehicles make a significant cut in that number, people will start to see human drivers as the more-difficult liability issue.
In your hypothetical situation, you'd probably deal with the owner's insurance company, just like with a human driver. The insurer will have already priced the policy lower based on underwriters' analysis that AI is safer than human drivers. In the case where the AI made an egregious error, I'm sure the insurer would be interested in pursuing legal action.
In my medium-sized metro area, I can recall at least a half-dozen deaths of cyclists this year caused by humans making similar errors. It doesn't take much for software to be better than that.
To me it just has to be better than human drivers, who are actually pretty awful. I think it's unfortunate that we all seem focused on having self-driving cars be basically perfect. If they were only twice as good as human drivers we should jump at the chance to reduce fatalities.
Recently got turned down for a job here, now I'm remarkably glad I did - this is an incredibly difficult problem to tackle, and they need absolutely brilliant people to achieve success.
I wish them the best of luck in their continued progress! I'll stick to easier stuff :)
They don't have to simulate one, merely reliably detect one and then refuse to drive. One of the most important lessons drilled into new drivers is that the best way to avoid accidents is to know when not to drive, self driving cars should not be an exception to that rule. If you are going to attempt to drive in hurricane you are essentially committing suicide, your best cause of action is to find a safe place to weather the storm. And if you really want to drive a self driving car might give you the option to override the safeties but those should only be used in actual emergencies, not just to putter around in really bad and possibly dangerous weather.
The same goes for dense fog, flooding and other situations where normal driving is no longer possible and/or responsible.
So during each winter storm, the roads will be lined with cars full of people freezing to death (literally) because their cars decided they can't drive home. And people trying to walk (in the roadway) to shelter, which isn't much safer.
Most cars can stay warm for several days just running the engine at idle. Assuming you get enough fresh air (not always a given in a snow storm that can block air vents) stopping and just running the engine for heat is safe unless your fuel tank is low - which it shouldn't be.
{kind=link}
If you want to do it right, you start with geometry. The first step is capturing range imagery and grinding it down to a 3D model of the world. This tells you where you physically can go. That's where we were at the DARPA Grand Challenge over a decade ago.
Then comes moving object popout. What out there isn't a stationary obstacle? That comes from processing multiple frames and range rate data from radars. Moving objects have to be tracked.
Only then does object recognition come into play. Moving objects should be classified if possible, and fixed objects of special interest (signs, barricades, etc.) identified. Not all objects will be identified, but that's OK. If it can't be identified and it's moving, you have to assume the worst case - it's vulnerable and it doesn't follow the road rules. This will force a slowdown and careful maneuvering around the unknown object. (See Chris Urmson's SXSW video of their vehicle encountering someone in a powered wheelchair chasing a duck with a broom.)
Predicting the behavior of moving objects is a big part of handling heavy traffic. That's what Google is working hard on now.
Machine learning is a part of this, but not the whole thing. You can't really trust machine learning; it's a statistical method and sometimes it will be totally wrong. You can trust geometry.
If you want to do it wrong, you start out with lane keeping and smart cruise control, tack on recognition of common objects, throw in some machine learning and hope for the best. This produced the Tesla self-crashing car, noted for running into unusual obstacles which partially block the lane and for trusting lane markings way too much. Look closely at the videos from Tesla and Cruise, slowing them down to real time. They speed them up so you can't easily see how bad the object recognition is.